This section details the datasets used in this study to calculate global population exposure to high concentrations of air pollution.
Air pollution data (PM2.5)
Rather than consider the cumulative load of all pollutants, this study looks at the differentiated exposure to anthropogenic PM2.5 pollution across countries. Particulate matter (PM) is one of the most common pollutants, primarily caused by fossil fuel combustion, such as car engines and coal or gas power plants10. Airborne PM is commonly categorized by the diameter of particles—PM2.5 for particles of up to 2.5 µm in diameter, and PM10 for those up to 10 µm in diameter—as this determines aerial transport, removal processes, and impacts within the respiratory tract3. This study focuses on PM2.5, for two main reasons. First, as one of the most pervasive and harmful pollutants, which can pass through the lungs into the bloodstream and affect other organs, PM2.5 is responsible for the vast majority of air pollution-related deaths, and its impacts are on the rise. It is estimated that 4.5 million people died in 2019 from adverse health effects related to long-term exposure to ambient air pollution, and that 4.1 million of these deaths were caused by PM2.5 (IHME 2020)31. And between 2000 and 2019, PM2.5-attributable deaths increased in all regions except Europe, Latin America, and North America6. Second, unlike many other pollutant types, datasets on PM2.5 spatial distribution and concentration levels are available with global coverage. Due to data limitations, this study does not cover indoor air pollution, another pervasive risk to health and well-being, especially in low- and middle-income countries.
We use the gridded dataset of ground-level fine particulate matter (PM2.5) concentrations provided by ref. 32, which offers both annual and monthly mean concentrations for 1998–2019, with global coverage and at 0.01-degree resolution (Fig. 6). The dataset is constructed by combining Aerosol Optical Depth satellite retrievals from the NASA MODIS, MISR, and SeaWIFS instruments with the GEOS-Chem chemical transport model, and subsequently calibrating to global ground-based observations using a geographically weighted regression. The 0.01-degree resolution (equivalent to about 1.1 km at the equator) is well suited for capturing regional variation in concentrations, but not granular local variations.
Fig. 6: PM2.5 concentrations in Southeast Asia. Estimates represent annual average concentrations in 2018, constructed based on satellite-based remote sensing data, global chemical transport modeling, and ground measurements. (Source: data by van Donkelaar et al. 2021). Full size image
As a globally modeled dataset, some uncertainty is to be expected, though sensitivity tests suggest good agreement with ground measurement32. More spatially nuanced analysis—for example, at a neighborhood or street level—would require alternative data based on local measures. It should also be noted that the chemical composition of PM2.5 particles can differ by pollution source33, and those associated with fossil fuel combustion are more toxic due to higher acidity levels (for example, sulfuric PM from coal burning). The global PM2.5 dataset can inform on total particle concentration, but not on acidity.
Population data
To estimate the location of people, we use the WorldPop Global High-Resolution Population dataset, produced by the University of Southampton, the World Bank, and other partners, which offers global coverage and is available yearly from 2000–20. WorldPop provides several datasets, including poverty, demographics, and urban change mapping. This study uses the population count map, a dataset in a raster format, that provides the number of inhabitants per cell, with a 3-arcsecond resolution, thus specifying the distribution of population. This information is based on administrative or census-based population data, disaggregated to grid cells based on distribution and density of built-up area, which is derived from satellite imagery34.
The choice of a population density map is important for estimating people’s exposure to natural hazards. Smith et al.35 provide a sensitivity analysis for flood exposure assessments using different population density maps, including WorldPop. They show that high-resolution population density maps perform best in capturing local exposure distribution, particularly the High-Resolution Settlement Layer (HRSL), jointly produced by Facebook, Columbia University, and the World Bank, which has 1-arcsecond or ~30-m resolution. But HRSL is only available for a limited number of countries, and WorldPop is shown to perform better than alternatives with global coverage, such as LandScan data (30-arcsecond, ~900-m resolution)36.
Subnational poverty rates
For 1755 of the 2183 subnational units, the World Bank’s Global Subnational Poverty Atlas offers poverty estimates, derived from the latest available Living Standards Measurement Survey for the respective country3. This harmonized inventory of household surveys offers ground-up empirical poverty estimates. Areas, where no poverty estimates are available tend to be high-income countries and small island states. This study uses the standard World Bank definitions of poverty—that is, daily expenditure thresholds of $1.90, $3.20, and $5.50—to determine the number of people living in poverty in a given subnational administrative unit.
Administrative boundaries
The definition of national administrative boundaries follows the standard World Bank global administrative map. However, national boundaries are further disaggregated into subnational units for all countries where World Bank household surveys are available with subnational representativeness. These subnational units are typically provinces or states but can also include custom groupings of subnational regions determined by the sampling strategy of household surveys. Overall, this study covers 211 countries, disaggregated into 2183 subnational units.
Methodology and stepwise computational process
To estimate the number of people exposed to unsafe air pollution levels, this study follows a computational process in four main steps, outlined here.
Step 1. Resample the PM2.5 data: First, we resample the air pollution map to ensure that pixels align with the gridded population density map to identify average annual PM2.5 concentration levels along a continuous scale.
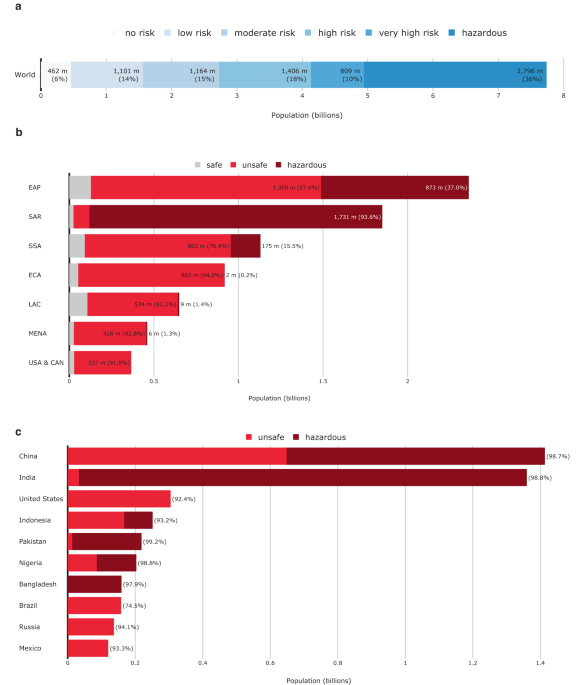
Step 2. Define air pollution risk categories: Second, we aggregate the values into six risk categories (Table 2), defined in line with the WHO’s Air Quality Guidelines3, which recommend an annual PM2.5 level of up to 5 µg/m3. For countries that exceed this threshold, it recommends interim targets at 10, 15, 25, and 35 μg/m3, corresponding to a linearly increasing mortality rate (Table 2). At higher concentrations, the concentration-response function of mortality may not be linear37. For each country, we assign each 1-degree cell one of the six risk categories, repeating this process for the world’s landmass of 149 million square kilometers, processing about 300 million data points.
Table 2 PM2.5 concentration thresholds based on the WHO Global Air Quality Guidelines Full size table
Step 3. Assign air pollution risk categories to population headcounts at the pixel level and aggregate to the administrative unit: As the air pollution and population density maps are converted into the same spatial resolution, we assign each population map cell a unique air pollution risk classification and aggregated them to the administrative unit (such as province or district) level. This allows us to calculate population headcounts for each risk category and for each (sub)national administrative unit, yielding an estimate of the number and share of people exposed to no, low, moderate, high, very high, and hazardous air pollution concentrations throughout the year. Finally, we aggregate these into administrative units—including country and subnational units—to yield regional and global estimates.
Step 4. Compute the number of people living in poverty and exposed to air pollution risk: In this final step, we multiply poverty shares with the estimated population headcount exposed to unsafe air pollution, to obtain an estimate of the number of people in each administrative unit living in poverty and exposed to air pollution risk. In the absence of pixel-level poverty share data, we use the World Bank’s Global Subnational Poverty Atlas for these calculations, which provide subnational-level data for at least 153 countries.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.