GPT-4o takes #1 & #2 on the Aider LLM leaderboards
Aider works best with LLMs which are good at editing code, not just good at writing code. To evaluate an LLM’s editing skill, aider uses a pair of benchmarks that assess a model’s ability to consistently follow the system prompt to successfully edit code.
The leaderboards below report the results from a number of popular LLMs. While aider can connect to almost any LLM, it works best with models that score well on the benchmarks.
GPT-4o
GPT-4o tops the aider LLM code editing leaderboard at 72.9%, versus 68.4% for Opus. GPT-4o takes second on aider’s refactoring leaderboard with 62.9%, versus Opus at 72.3%.
GPT-4o did much better than the 4-turbo models, and seems much less lazy.
GPT-4o is also able to use aider’s established “diff” edit format that uses SEARCH/REPLACE blocks. This diff format is used by all the other capable models, including Opus and the original GPT-4 models The GPT-4 Turbo models have all required the “udiff” edit format, due to their tendancy to lazy coding.
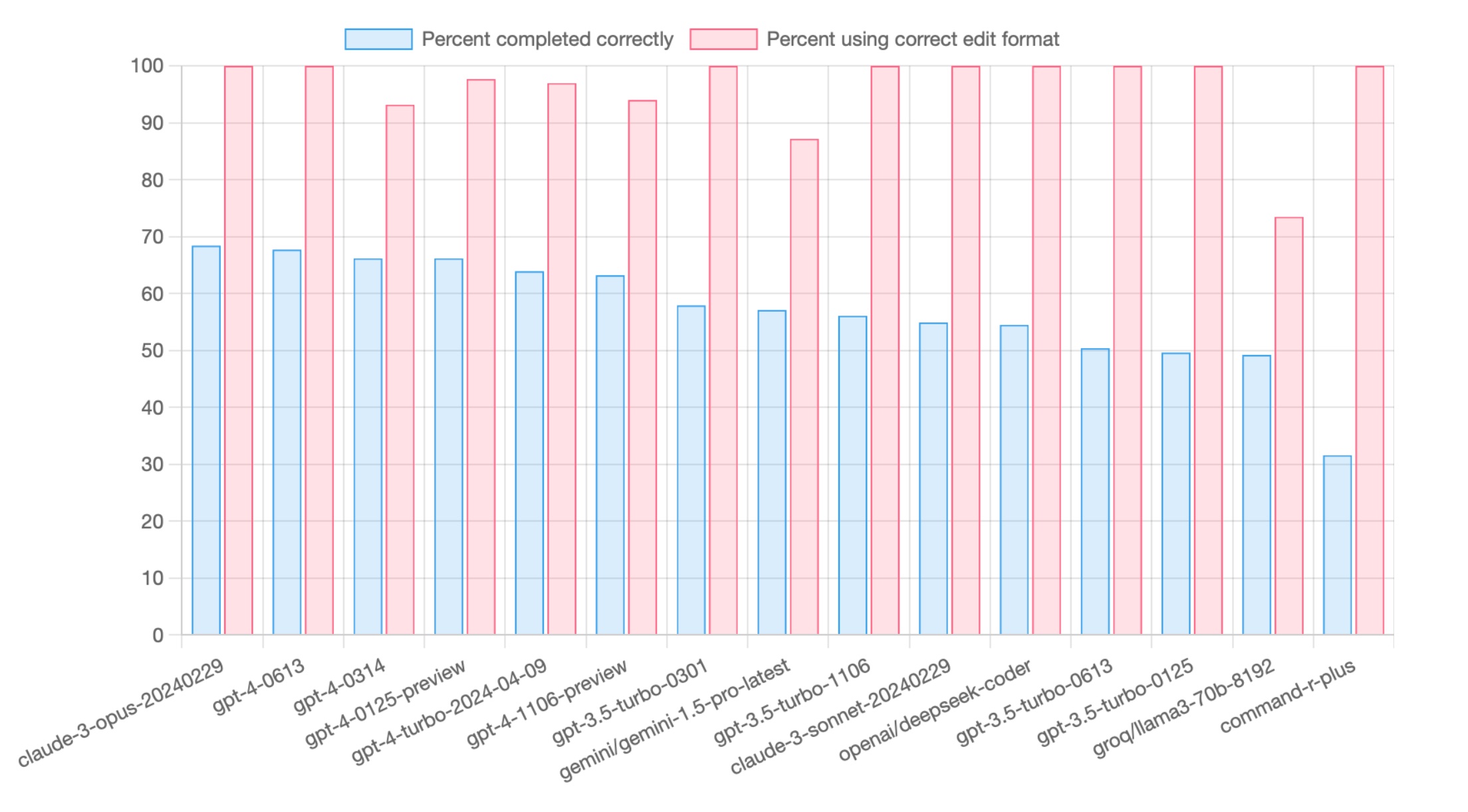
Code editing leaderboard
Aider’s code editing benchmark asks the LLM to edit python source files to complete 133 small coding exercises. This benchmark measures the LLM’s coding ability, but also whether it can consistently emit code edits in the format specified in the system prompt.
Model Percent completed correctly Percent using correct edit format Command Edit format openai/gpt-4o 72.9% 96.2% aider diff claude-3-opus-20240229 68.4% 100.0% aider --opus diff gpt-4-0613 67.7% 100.0% aider -4 diff gpt-4-0314 66.2% 93.2% aider --model gpt-4-0314 diff gpt-4-0125-preview 66.2% 97.7% aider --model gpt-4-0125-preview udiff gpt-4-1106-preview 65.4% 92.5% aider --model gpt-4-1106-preview udiff gpt-4-turbo-2024-04-09 63.9% 97.0% aider --gpt-4-turbo udiff deepseek-chat v2 (diff) 60.9% 97.0% aider --model deepseek/deepseek-chat diff deepseek-chat v2 (whole) 60.2% 100.0% aider --model deepseek/deepseek-chat --edit-format whole whole gpt-3.5-turbo-0301 57.9% 100.0% aider --model gpt-3.5-turbo-0301 whole gemini-1.5-pro-latest 57.1% 87.2% aider --model gemini/gemini-1.5-pro-latest diff-fenced gpt-3.5-turbo-1106 56.1% 100.0% aider --model gpt-3.5-turbo-1106 whole claude-3-sonnet-20240229 54.9% 100.0% aider --sonnet whole deepseek-coder 54.5% 100.0% aider --model deepseek/deepseek-coder whole gpt-3.5-turbo-0613 50.4% 100.0% aider --model gpt-3.5-turbo-0613 whole gpt-3.5-turbo-0125 50.4% 100.0% aider -3 whole llama3-70b-8192 49.2% 73.5% aider --model groq/llama3-70b-8192 diff WizardLM-2 8x22B 44.4% 100.0% aider --model openrouter/microsoft/wizardlm-2-8x22b whole qwen1.5-110b-chat 37.6% 100.0% aider --model together_ai/qwen/qwen1.5-110b-chat whole command-r-plus 31.6% 100.0% aider --model command-r-plus whole
Code refactoring leaderboard
Aider’s refactoring benchmark asks the LLM to refactor 89 large methods from large python classes. This is a more challenging benchmark, which tests the model’s ability to output long chunks of code without skipping sections or making mistakes. It was developed to provoke and measure GPT-4 Turbo’s “lazy coding” habit.
The refactoring benchmark requires a large context window to work with large source files. Therefore, results are available for fewer models.
Model Percent completed correctly Percent using correct edit format Command Edit format claude-3-opus-20240229 72.3% 79.5% aider --opus diff openai/gpt-4o 62.9% 53.9% aider diff gpt-4-1106-preview 50.6% 39.3% aider --model gpt-4-1106-preview udiff gemini/gemini-1.5-pro-latest 49.4% 7.9% aider --model gemini/gemini-1.5-pro-latest diff-fenced gpt-4-turbo-2024-04-09 34.1% 30.7% aider --gpt-4-turbo udiff gpt-4-0125-preview 33.7% 47.2% aider --model gpt-4-0125-preview udiff
Notes on benchmarking results
The key benchmarking results are:
Percent completed correctly - Measures what percentage of the coding tasks that the LLM completed successfully. To complete a task, the LLM must solve the programming assignment and edit the code to implement that solution.
- Measures what percentage of the coding tasks that the LLM completed successfully. To complete a task, the LLM must solve the programming assignment and edit the code to implement that solution. Percent using correct edit format - Measures the percent of coding tasks where the LLM complied with the edit format specified in the system prompt. If the LLM makes edit mistakes, aider will give it feedback and ask for a fixed copy of the edit. The best models can reliably conform to the edit format, without making errors.
Notes on the edit format
Aider uses different “edit formats” to collect code edits from different LLMs. The “whole” format is the easiest for an LLM to use, but it uses a lot of tokens and may limit how large a file can be edited. Models which can use one of the diff formats are much more efficient, using far fewer tokens. Models that use a diff-like format are able to edit larger files with less cost and without hitting token limits.
Aider is configured to use the best edit format for the popular OpenAI and Anthropic models and the other models recommended on the LLM page. For lesser known models aider will default to using the “whole” editing format since it is the easiest format for an LLM to use.
Contributing benchmark results
Contributions of benchmark results are welcome! See the benchmark README for information on running aider’s code editing benchmarks. Submit results by opening a PR with edits to the benchmark results data files.