May 14, 2024
[AINews] Google I/O in 60 seconds
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it ????
Spot the 7 flavors of Gemini!
AI News for 5/13/2024-5/14/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (426 channels, and 8590 messages) for you. Estimated reading time saved (at 200wpm): 782 minutes.
Google I/O is still ongoing, and it is a good deal harder to cover than OpenAI's half-hour event yesterday because of the sheer scope of products, and we haven't yet come across a single webpage that summarizes everything (apart from @Google and @OfficialLoganK accounts).
Here is a subjectively sorted list:
The Gemini Model Family
The Gemma Model Family
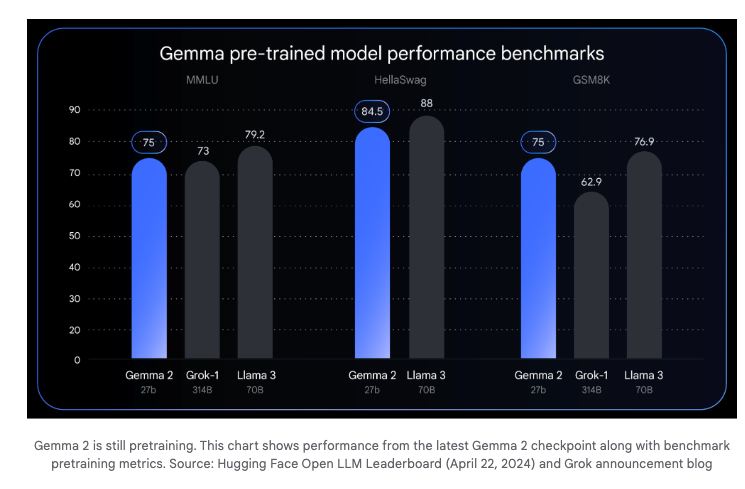
Gemma 2, now up to 27B (previously 7B and 2B), a still-in-training model that offers near-Llama-3-70B performance at half the size (fitting in 1 TPU)
PaliGemma - their first vision-language open model inspired by PaLI-3, complementing CodeGemma and RecurrentGemma.
Other Launches
And AI deployments across Google's product suite - Workspace, Email, Docs, Sheets, Photos, Search Overviews, Search with Multi-step reasoning, Android Circle to Search, Lens.
Overall a very competently executed I/O, easy to summarize without losing too much detail. The world awaits Apple's answer.
Table of Contents
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
GPT-4o Release by OpenAI
Key Features : @sama noted GPT-4o is half the price and twice as fast as GPT-4-turbo , with 5x rate limits . @AlphaSignalAI highlighted its ability to reason across text, audio, and video in real time , calling it extremely versatile and fun to play with .
: @sama noted GPT-4o is , with . @AlphaSignalAI highlighted its ability to , calling it . Multimodal Capabilities : @gdb emphasized GPT-4o's real-time reasoning across text, audio, and video , seeing it as a step towards more natural human-computer interaction .
: @gdb emphasized GPT-4o's , seeing it as a . Improved Tokenizer : @aidan_clark mentioned up to 9x cheaper/faster performance for non-Latin-script languages thanks to the new tokenizer .
: @aidan_clark mentioned . Wide Availability: @sama stated GPT-4o is available to all ChatGPT users, including the free plan, in line with their mission of democratizing access to powerful AI tools.
Technical Analysis and Implications
Architecture Speculation : @DrJimFan speculated GPT-4o maps audio to audio directly as a first-class modality , requiring new tokenization and architecture research . He believes OpenAI developed a neural-first, streaming video codec to transmit motion deltas as tokens .
: @DrJimFan speculated GPT-4o , requiring . He believes OpenAI developed a . Potential GPT-5 Relation : @DrJimFan suggested GPT-4o may be an early checkpoint of GPT-5 that's still training , with the branding betraying insecurity ahead of Google I/O.
: @DrJimFan suggested GPT-4o may be an , with the branding betraying insecurity ahead of Google I/O. Character AI Overlap : @DrJimFan noted the assistant's lively, flirty personality similar to the AI from "Her" , and believes OpenAI is directly competing with Character AI's form factor .
: @DrJimFan noted the assistant's , and believes OpenAI is . Apple Integration Potential: @DrJimFan outlined 3 levels of iOS integration: 1) Replacing Siri with on-device GPT-4o, 2) Native features for camera/screen streaming, 3) Integration with iOS system APIs. He believes the first to partner with Apple will have an AI assistant with a billion users from the start.
Community Reactions and Memes
@karpathy joked that " The killer app of LLMs is Scarlett Johansson ", rather than math or other serious applications.
", rather than math or other serious applications. @vikhyatk shared a meme of Steve Ballmer's "developers" chant , questioning if any big tech CEOs still show that level of enthusiasm.
, questioning if any big tech CEOs still show that level of enthusiasm. @fchollet quipped that with the rise of AI girlfriends, "self-play" in AI might finally become a reality, referencing a concept discussed since 2016.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
GPT-4o Capabilities and Features
GPT-4o Availability and Pricing
Reactions and Comparisons
Open Source and Competitors
Memes and Humor
AI Discord Recap
A summary of Summaries of Summaries
Claude 3 Sonnet
Here are the top 3-4 major themes from the content, with important key terms, facts, URLs, and examples bolded:
Claude 3 Opus
Falcon 2 and Other Open Models Impress: Falcon 2 11B was released, outperforming Meta's Llama 3 8B and nearing Google's Gemma 7B with open-source, multilingual and multimodal capabilities. Anticipation also grew for Gemma 2, Google's upcoming 27B open model. Users debated the accessibility and future of open vs closed models.
Anthropic's Opus Policy Shift Sparks Debate: Anthropic's new terms for Opus, banning certain content types, generated mixed reactions. Despite GPT-4o's speed, some still preferred Claude 3 Opus for its strong summarization and human-like output.
Memory and Multi-GPU Support Coming to Unsloth: Unsloth AI teased upcoming features like cross-session memory for custom GPTs and multi-GPU support. The platform celebrated 1M model downloads as users explored optimal fine-tuning datasets and methods.
Modular's Mojo Language Expands with Key Talks: Modular shared educational content on Mojo's ownership model and open-source standard library contributions. Mojo's compiler, written in C++, generated interest in potential MLIR integration and future self-hosting.
GPT4T (gpt-4-turbo-2024-04-09)
Major Themes:
Advancement of AI Models: Various channels buzz with discussions about the latest AI models, like GPT-4o, Falcon 2, and LLaMA models. These models boast enhanced capabilities like multimodal functionalities and real-time processing, with integration into platforms such as Perplexity AI and OpenRouter. Community Engagement and Collaborations: There's an increasing interest in sharing projects, seeking collaborations, and participating in discussions around coding practices, optimizations, and the integration of new technologies within community platforms such as Stability.ai, Modular, and LAION, demonstrating a thriving ecosystem focused on collective growth and learning. Customization and Personalization Questions: Users show a keen interest in customizing AI models and systems to fit specific needs, ranging from setting up private instances of AI tools to merging different model capabilities, reflecting an ongoing trend of personalizing AI use to meet individual or organizational requirements. Technical Challenges and Debugging: A common thread across several discords centers around troubleshooting and problem-solving specific to AI models and computing environments. This includes discussions on optimizing model inference, handling specific library issues, and improving integration with various coding environments. Educational Content and Resource Sharing: Several channels are dedicated to educational content ranging from detailed explanations of machine learning concepts to sharing tutorials and resources to help members learn about and implement AI technologies. This not only helps in skill development but also fosters a culture of knowledge sharing within the community.
GPT4O (gpt-4o-2024-05-13)
Model Launches and Innovations: GPT-4o : Many discords are abuzz with OpenAI's launch of GPT-4o , a multimodal model capable of handling text, audio, and vision inputs. This model promises significant advancements in speed, context windows (up to 128K tokens), and overall capabilities. OpenAI's GPT-4o is praised for real-time multimodal capabilities but also criticized for some quirks and high usage costs (GPT-4o Info).
: Many discords are abuzz with OpenAI's launch of , a multimodal model capable of handling text, audio, and vision inputs. This model promises significant advancements in speed, context windows (up to 128K tokens), and overall capabilities. OpenAI's GPT-4o is praised for real-time multimodal capabilities but also criticized for some quirks and high usage costs (GPT-4o Info). Falcon 2 : Highlighted as a competitive model against Meta's Llama 3 8B and Google's Gemma 7B. It is praised for being open-source, multilingual, and multimodal. Falcon 2 Announcement.
: Highlighted as a competitive model against Meta's Llama 3 8B and Google's Gemma 7B. It is praised for being open-source, multilingual, and multimodal. Falcon 2 Announcement. Claude 3 Opus: Its strength lies in handling long-form reasoning tasks and text summarization despite facing cost and policy concerns. Claude 3 Opus. Performance and Technical Discussions: GPU Utilization : Many discussions revolve around optimizing GPU usage for different models such as Stable Diffusion , YOLOv1 , and implementation techniques in Flash Attention 2 . This includes guide sharing and configuration tips like the effectiveness of ThunderKittens in speeding up inference and training (GitHub - ThunderKittens).
: Many discussions revolve around optimizing GPU usage for different models such as , , and implementation techniques in . This includes guide sharing and configuration tips like the effectiveness of in speeding up inference and training (GitHub - ThunderKittens). API and Performance Enhancements: Conversations on API performance specifically focus on optimizing response times and handling larger context windows. For instance, GPT-4o API is noted for faster speed and better performance at reduced costs. Community Tools and Support: Projects and Tools Sharing : From job search assistants using Retrieval-Augmented Generation to detailing steps for setting up AI tools like OpenRouter with community-developed utilities. There is significant sharing of personal projects and collaborative efforts (Job Search Assistant Guide, OpenRouter Model Watcher).
: From job search assistants using to detailing steps for setting up AI tools like with community-developed utilities. There is significant sharing of personal projects and collaborative efforts (Job Search Assistant Guide, OpenRouter Model Watcher). Help and Collaboration: A recurring theme is troubleshooting and providing support for issues encountered during AI development, such as CUDA errors, model fine-tuning, and dependency management. Ethics and Policy: Content Moderation and Policies : ETHICAL concerns around the usage and policies governing AI tools, specifically Claude 3 Opus and GPT-4o moderation filters (Anthropic Policy Link).
: ETHICAL concerns around the usage and policies governing AI tools, specifically and moderation filters (Anthropic Policy Link). Open-Source vs Proprietary Models: Discussions often compare open-source advantages like Falcon 2 against proprietary models' constraints, impacting their accessibility and modifications.
PART 1: High level Discord summaries
OpenAI Discord
GPT-4o Makes Its Grand Entrance: OpenAI launched a new model, GPT-4o, with free access for certain features and additional benefits for Plus users, including faster response times and more extensive features. GPT-4o distinguishes itself by processing audio, vision, and text in real-time, indicating a significant step forward in multimodal applications with text and image inputs already available and voice and video to be rolled out soon. Read more about GPT-4o.
Claude Claims Complex Task Crown: Within the community, Claude Opus is considered superior for complex, long-form reasoning compared to GPT-4o, particularly when processing extensive original content. Expectations are high for future enhancements that include broader context windows and advanced voice capabilities from both Google and OpenAI.
Custom GPTs Await Memory Upgrade: The awaited cross-session context memory for custom GPTs remains in development, with an assurance that once released, memory will be configurable by the creators per GPT. Enhanced speeds and consistent API performance mark the current state of GPT-4o, though Plus users benef from higher message limits, and everyone eagerly awaits the promised integration within custom GPT models.
Prompt Engineering Exposes Model Quirks: Users faced challenges when directing GPT-4o towards creative and spatially aware tasks, noting difficulties in iterative image generation and specific content moderation issues with Gemini 1.5's safety filters. Even as GPT-4o accelerates response times, it occasionally stumbles in comprehension and execution, indicating room for iterative refinement based on user feedback.
Monitored ChatGPT Clone Sought: A member inquired about creating a ChatGPT-like application that allows organizational monitoring of messages using the GPT-3.5 model. This reflects a growing need for customizable and controllable AI tools within formal ecosystems.
Perplexity AI Discord
GPT-4's Token Tussle: There's debate around GPT-4's token capacity, with clarification that GPT-4's larger context window applies to specific models like GPT-4o which has a 128K token context window. Some users are diving into the capabilities of GPT-4o, noting its velocity and performance excellence, and sharing video examples of its real-time reasoning.
Policy Shift Sparks Chatter: Anthropic's revised terms of service for Opus, going live on June 6th, have members in a stir due to limitations like the ban on creating LGBTQ content. Details of the policy can be found in the shared Anthropic policy link.
Claude Maintains Its Ground: Despite the buzz around GPT-4o, Claude 3 Opus is still the go-to for text summarization and human-like responses for some users, despite concerns over cost and use restrictions.
Perplexity's New Power Player: Users are testing GPT-4o's integration into Perplexity's tools, highlighting its high-speed, in-depth responses. The Pro version allows for 600 queries a day, echoing its API availability.
API Config Conundrums: Discussions surfaced around Perplexity's API settings, with a user inquiring about timeout issues for lengthy inputs using llama models. One member indicated that the chat model of llama-3-sonar-large-32k-chat is fine-tuned for dialogue contexts, yet no consensus on the optimal timeout settings was reported.
LLaMA Instruction Tuning Advice: For finetuning on small datasets, start with the instruction model of Llama-3 before considering the base model if performance is suboptimal, as per users’ discussions. They recommend iteration to find the best fit for your scenario.
ThunderKittens Exceeds Flash Attention 2: ThunderKittens overtakes Flash Attention 2 in speed, per mentions in the community, promising faster inference and potential advancements in training speeds. The code is available on GitHub.
Synthetic Dataset Construction for Typst: To effectively fine-tune models on "Typst," engineers propose synthesizing 50,000 examples. The daring task of generating substantial synthetic datasets has been been flagged as a fundamental step for progress.
Multimodal Model Expansion on Unsloth AI: Upcoming support for multimodal models has been anticipated in Unsloth AI, including multi-GPU support expected next week, setting a pace for new robust AI capabilities.
A Million Cheers for Unsloth AI: The AI community celebrates Unsloth AI surpassing one million model downloads on Hugging Face, signaling a milestone recognized by users and reflecting the community’s active engagement and support.
Latent Space Discord
Apple Aims for AI Integration, Lifts an Eyebrow on Google: Amidst the tech talk, speculations tally on Apple's rumored deal with OpenAI to incorporate ChatGPT into iPhones, juxtaposing the idea of local versus cloud-based models. Skepticism brews among engineers over the feasibility of this integration, with some doubting Apple's ability to host heavyweight models efficiently on handheld devices.
Falcon 2 Soars Above the Rest: The Falcon 2 model gains applause for its performance, boasting open-source, multilingual, and multimodal capabilities while edging out competitors like Meta's Llama 3 8B and slightly trailing behind Google Gemma 7B's benchmarks. Evident excitement trails the announcement that Falcon 2 is both open-source and superior in several areas Falcon LLM.
GPT-4o Stirring the Pot: Gasps and groans tune into the conversation around GPT-4o, OpenAI's newest model that flexes faster response times and intriguing free chat capabilities. Critiques hover around its branding and performance concerns—particularly latency—despite the buzz over poem-laureate-quick capabilities.
Voice Meets Vision, Sets the Stage for AI Drama: The demonstration of ChatGPT's voice and vision integration commands attention, with its show of real-time, emotion-sensitive AI interactions. Doubts infiltrate the guild about the reality of the demo's capabilities, poking at the potential behind-the-scenes mechanics of such a display.
API Anticipation and the Competitive Landscape: Discussions spin around accessing GPT-4o's API, with engineers leaning forward for its swift performance. The undercurrent reflects on the greater AI battlefield, where Google and other players shuffle in reaction to OpenAI's gambit with GPT-4o—and the community watches, waiting to play their own hand with the new API.
Nous Research AI Discord
LLM Struggles to Exceed 8k Tokens : Some members reported challenges in using Llama 3 70b in creating coherent outputs beyond 8k tokens. While notable successes have been achieved, there is room for improvements in handling larger token processes.
: Some members reported challenges in using in creating coherent outputs beyond 8k tokens. While notable successes have been achieved, there is room for improvements in handling larger token processes. Riding the Roller Coaster of GPT-4o : Mixed reactions and reviews flooded the server following the advent of OpenAI’s GPT-4o model. Some noted unique capabilities, including real-time multimodal functionality and Chinese token handling, while others scrutinized its limitations, especially regarding its image editor mode and cost efficiency.
: Mixed reactions and reviews flooded the server following the advent of OpenAI’s GPT-4o model. Some noted unique capabilities, including real-time multimodal functionality and Chinese token handling, while others scrutinized its limitations, especially regarding its image editor mode and cost efficiency. Remote Automation: Trickier Than You Think : Demonstrating the intricacies and subtleties of the AI field, the community shared experiences and ideas about automating software that runs inside a Remote Desktop Protocol. From parsing the Document Object Model (DOM) to reverse engineering software, the conversation showcased the complicated navigation and decision-making paths in automation processes.
: Demonstrating the intricacies and subtleties of the AI field, the community shared experiences and ideas about automating software that runs inside a Remote Desktop Protocol. From parsing the Document Object Model (DOM) to reverse engineering software, the conversation showcased the complicated navigation and decision-making paths in automation processes. Heads or Tails: Renting Vs Owning GPU Setups for LLMs : The assembly hosted a hearty debate about the pros and cons of renting vs owning GPU setups for use with large language models (LLMs) . The conversation took a deep dive into cost-effectiveness, privacy considerations, and hardware specifications, with GPU providers and setup configurations being extensively explored.
: The assembly hosted a hearty debate about the pros and cons of renting vs owning GPU setups for use with large language models . The conversation took a deep dive into cost-effectiveness, privacy considerations, and hardware specifications, with GPU providers and setup configurations being extensively explored. Multimodality of GPT-4o Unveiled : Unraveling the futuristic promise of GPT-4o, community members dived into enlightening exchanges about the model’s multimodal features, particularly whispering latents for audio inputs and non-English language token handling. The community also pointed out resources to understand the longest Chinese tokens and tokenizer improvements in models like GPT4-o.
: Unraveling the futuristic promise of GPT-4o, community members dived into enlightening exchanges about the model’s multimodal features, particularly whispering latents for audio inputs and non-English language token handling. The community also pointed out resources to understand the longest Chinese tokens and tokenizer improvements in models like GPT4-o. WorldSim Images Making Their Mark : WorldSim users openly admire the program's creativity. One member even mentioned considering an artwork-inspired tattoo, demonstrating their appreciation for WorldSim's visuals.
: WorldSim users openly admire the program's creativity. One member even mentioned considering an artwork-inspired tattoo, demonstrating their appreciation for WorldSim's visuals. IBM/Redhat Takes LLMs the Extra Mile : IBM/Redhat’s schema for expanding the knowledge base and capabilities of LLMs was a hot topic. Their project assimilates new information on a continuum, applying it real-time instead of requiring full retraining after each knowledge expansion, presenting an innovative approach for models' incremental evolution.
: IBM/Redhat’s schema for expanding the knowledge base and capabilities of LLMs was a hot topic. Their project assimilates new information on a continuum, applying it real-time instead of requiring full retraining after each knowledge expansion, presenting an innovative approach for models' incremental evolution. Researchers Seek Human/LLM Text Pairs for Comparative Model Evaluation : The extraction of datasets comparing 'human_text' and 'llm_text' for the same prompts arose during discussions, suggesting a need for a deeper comparison and evaluation of LLM responses in relation to human language outputs.
: The extraction of datasets comparing 'human_text' and 'llm_text' for the same prompts arose during discussions, suggesting a need for a deeper comparison and evaluation of LLM responses in relation to human language outputs. Enriching AI Knowledge Through Open Project Contributions: The feasibility and importance of community contributions towards open projects such as IBM/Redhat’s Granite and Merlinite were affably reiterated - a step towards open source collaborations for a tech-transformed future.
CEO Shuffles at Stability.ai : Discussion centered around Stability AI 's uncertain future with CEO Emad's exit and the murky release status of SD3 , including whether it might become a paid service.
: Discussion centered around 's uncertain future with CEO Emad's exit and the murky release status of , including whether it might become a paid service. GPU Showdown for Stable Diffusion : Engineers debated on the best GPUs for running Stable Diffusion , reaching a consensus that those with more VRAM are better suited, and shared a comprehensive guide on styles and tags.
: Engineers debated on the best GPUs for running , reaching a consensus that those with more VRAM are better suited, and shared a comprehensive guide on styles and tags. Inpainting Boost with BrushNet : The integration of BrushNet via ComfyUI BrushNet's GitHub repository was recommended for improved inpainting in Stable Diffusion, utilizing a combo of brush and powerpaint features.
: The integration of BrushNet via ComfyUI BrushNet's GitHub repository was recommended for improved inpainting in Stable Diffusion, utilizing a combo of brush and powerpaint features. Strategies for Consistent AI Characters : Techniques to maintain AI character consistency were hotly debated, with a focus on LoRA and ControlNet , and resources for creating detailed character sheets.
: Techniques to maintain AI character consistency were hotly debated, with a focus on and , and resources for creating detailed character sheets. Big Tech vs. Open Community Models: Google's Imagen 3 prompted discussions reflecting a mix of anticipation and preference for open models like SD3, due to the communal accessibility.
LM Studio Discord
Fine-Tuning and VPN Workarounds: Engineers confirmed that accessing a fine-tuned model stored on Hugging Face through LM Studio is possible if public and using the GGUF format. Additionally, VPN usage was suggested to remedy network errors from Hugging Face being blocked, pointing to region-specific restrictions and recommending IPv4 connections.
Model Performance Discussions: The community discussed model merging strategies, such as applying methods from unsloth to potentially merge and upgrade the llama3 and/or mistral. Furthermore, there was a debate surrounding different quant levels for models, highlighting that anything below Q4 is seen as inefficient.
Software Compatibility and Hardware: Discussions indicated incompatibilities, such as the Command R model outputs on Apple M1 Max systems, and ROCM limitations with the RX6600 GPU resulting in issues with LM Studio and Ollama. Concerning hardware, talks favored GPUs like the Nvidia 3060ti for value-for-money in LM Studio applications and the significance of VRAM speed for efficient LLM inference.
LM Studio Feature Set and Support: Queries were raised about multimodal functionality in LM Studio, specifically regarding feature consistency with standard models. Moreover, Intel GPU support interest was expressed, with offers from an Intel employee to help with SYCL integration, pointing to potential performance improvements.
Feedback, Expectations, and Future Directions: There was critical feedback on LMS's current realtime learning capabilities, with user demands for at least a differential file for line-item training. Another user suggested the deployment of larger models like command-r+ or yi-1.5 for possibly enhanced outcomes.
Deployment Considerations: A member evaluated the Meta-Llama-3-8B-Instruct-Q4_K_M model's high RAM usage over GPU, weighing deployment options between AWS and commercial APIs in the context of cost-effectiveness. They compared the potential savings of using IaaS providers against subscriptions with LLMaaS considering the significant differences in model sizes and parameters.
HuggingFace Discord
YOCO Cuts Down on GPU Needs: The YOCO paper introduces a new decoder-decoder architecture that cuts GPU memory usage while speeding up the prefill stage, maintaining global attention capabilities.
When NLP and AI Storytelling Collide: Researchers are pulling from the Awesome-Story-Generation GitHub repository to contribute to comprehensive studies on AI story generation, such as the GROVE framework, aimed at increasing story complexity.
Stable Diffusion Ventures into DIY Territory: A Fast.ai course spans over 30 hours, teaching Stable Diffusion from scratch, partnering with industry insiders from Stability.ai and Hugging Face, discussed alongside queries about sadtalker installation and practical uses for transformer agents.
OCR Quality Frontier: A collection of OCR-quality classifiers showcases the feasibility of distinguishing between clean and noisy documents using compact models.
Stable Diffusion and YOLO: A HuggingFace guide on Stable Diffusion using Diffusers is available, and conversations revolve around YOLOv1 implementations using ResNet18, balancing data quality and quantity issues to improve model performance.
Mixed Sentiments on the Cutting Edge: GPT-4o's announcement led to diverse reactions within the community, raising concerns about distinguishing AI from humans, while members reported mixed success with custom tokenizer creation and NLP strategies focused on example-rich prompts.
New Multimodal Models Storm OpenRouter: OpenRouter has expanded its lineup with the launch of GPT-4o, noted for supporting text and image inputs, and LLaVA v1.6 34B. Additionally, the roster now includes DeepSeek-v2 Chat, DeepSeek Coder, Llama Guard 2 8B, Llama 3 70B Base, Llama 3 8B Base, with GPT-4o's latest iteration dating May 13, 2024.
Blazing through Beta: An advanced research assistant and search engine is being beta-tested, offering premium access with leading models like Claude 3 Opus and Mistral Large, and the platform shared a promo code RUBIX for trials.
GPT-4o Enthusiasm and Scrutiny: A vivacious discussion about GPT-4o's API pricing ($5/15 per 1M tokens) sparked excitement, whereas speculation about its multimodal capabilities has piqued curiosity, with commentators noting the lack of native image handling via OpenAI's API.
Community Weighs in on OpenRouter Hiccups: Technical difficulties with OpenRouter were voiced by users, identifying issues such as empty responses and errors from models like MythoMax and DeepSeek. Alex Atallah clarified that most models on OpenRouter are FP16, with some quantized exceptions.
Engineering Connection over Community Tools: A community-developed tool to sort through OpenRouter models has been positively received, with suggestions to integrate additional metrics like ELO scores and model add-dates being discussed. Links to related resources such as OpenRouter API Watcher were provided.
GPT-4o Leads the Frontier: OpenAI's GPT-4o sets a new benchmark in AI capabilities, especially in reasoning and coding, dominating LMSys arena and featuring a doubled token capacity thanks to a tokenizer update. Its multi-modal prowess was also showcased including potential singing abilities, stirring both interest and debate around AI evolution and its competitive landscape.
REINFORCE Under PPO's Umbrella: The AI community discusses a new PR from Hugging Face that positions REINFORCE as a subset of PPO, detailed in a related paper, showing active contributions in the realm of reinforcement learning.
AI's Silver Screen Reflects Real Concerns: Dialogues within the community resonate with the movie "Her", highlighting how AI interaction can be perceived as either trivial or profound. These discussions tie in with sentiments regarding AI leadership and the humanization of technology.
Long-Term AI Governance Emerging: Forward-looking conversations hint at Project Management Robots (PRMs) playing a key role in guiding long-term AI tasks, inspired by a talk by John Schulman.
Evaluating AI Evaluation: A detailed blog post stirred thoughts about the accessibility and future of large language model (LLM) evaluations, discussing tools ranging from MMLU benchmarks to A/B testing and its implications for academia and developers.
Eleuther Discord
MLP Might Take the Crown: There's a buzz about MLP-based models possibly overtaking Transformers in vision tasks, with a new hybrid approach presenting fierce competition. A specific study highlights the efficiency and scalability of MLPs, despite some doubts regarding their sophistication.
Getting the Initialization Right: Debate emerged on the criticality of initialization schemes in neural networks, especially for MLPs, with suggestions that innovation in initialization could unlock vast improvements. A notion was floated about creating initializations via Turing machines, exploring the frontier of synthetic weight generation as seen on Gwern's website.
Mimetic Initialization as a Game-Changer: A paper promoting mimetic initialization surfaced, advocating for this method as a boost for Transformers working with small datasets, resulting in greater accuracy and reduced training times, detailed in MLR proceedings.
Scalability Quest Continues: In-depth discussions tackled whether MLPs can surpass Transformers in terms of Model FLOPs Utilization on various hardware, hinting that even small MFU improvements could resonate across large scales.
Contemplating NeurIPS Contributions: A call was made for potential last-minute NeurIPS submissions, with one member citing interest in topics akin to the Othello paper. Another discussion queried the consequences of model compression on specialized features and their relation to training data diversity.
New Sheriff in Town: Mojo Compiler Development Heats Up: Engineering discussions revealed keen interest in contributing to the Mojo compiler, though it's not yet open source. The compiler debate also unveiled that it's written in C++, with aspirations to rebuild MLIR in Mojo spark curiosity among contributors.
MLIR Makes Friends with Mojo: Integration features between Mojo and MLIR were dissected, highlighting how Mojo's compatibility with MLIR could lead to a self-hosting compiler in the future. Contributions to the Mojo Standard Library are now encouraged, with a how-to video from Modular engineer Joe Loser illuminating the process.
Cutting-Edge Calendars: Upcoming Mojo Community Meeting details were announced for May 20, with the aim to keep developers, contributors, and users engaged with Mojo's trajectory. A helpful meeting document and options to add events via a community meeting calendar were shared to coordinate.
Nighttime is the Right Time for Code: Nightly releases of mojo are now more frequent, a welcomely aggressive update schedule that aims at transforming nightly nightlies from dream to reality. However, a segfault issue in nested arrays remains controversial, and there's talked-about adjusting release frequency to avoid confusion over compiler versions among users.
Coding Conundrums and Compiler Conversations: Within the dusty digital hallways, developers tackled topics from how to restict parameters to float types in Mojo—advised to use dtype.is_floating_point() —to Python's mutable default parameters, and the use of FFI to call C/C++ libraries from Mojo. Further details were shared through a GitHub link on the subject of FFI in Mojo.
CUDA MODE Discord
ZeRO-1 Upscaling Amps Up Training Throughput: Implementing ZeRO-1 optimization increased per GPU batch size from 4 to 10 and improved training throughput by about 54%. Details about the merge and its effect can be reviewed on the PR page.
ThunderKittens Sparks Curiosity: Discussion included interest in HazyResearch/ThunderKittens, a CUDA tile primitives library, for its intriguing potential to optimize LLMs, drawing comparisons with Cutlass and Triton tools.
Triton Gains Through FP Enhancements: Updates to Triton included performance improvements with FP16 and FP8, as shown in benchmark data: "Triton [FP16]" achieved 252.747280 for N_CTX of 1024 and "Triton [FP8]" reached 506.930317 for N_CTX of 16384.
CUDA Streamlines, but Questions Remain: On integrating custom CUDA kernels in PyTorch, resources were shared, including a YouTube lecture addressing the basics, while issues like clangd parsing .cu files and function overhead in cuSPARSE were flagged.
Finessing CUDA CI Pipelines: The need for GPU testing in continuous integration was debated, promoting GitHub's latest GPU runner support in CI as a sought-after update for robust pipeline construction.
LlamaIndex Discord
Hack the Llama with New Use Cases: A new set of cookbooks showcases seven different use cases for Llama 3, detailed in a celebratory post for the recent hackathon; the cookbook is accessible here.
Day Zero GPT-4o Integration: Enthusiasm brews as GPT-4o sees support in Python and TypeScript from its inception, with instructions for installation via pip detailed here and notes highlighting its multi-modal capabilities.
Multimodal Marvel and SQL Speed: A compelling multimodal demo of GPT-4o is up, alongside a revelation of GPT-4o outpacing GPT-4 Turbo in SQL query efficiency; see the demo here and performance details here.
Melding LlamaIndex Metadata and Errors: Amidst discussions, clarity emerged that metadata filtering can be managed by LlamaIndex, with manual inclusions necessary for specifics like URLs; also noted was advice given to troubleshoot Unexpected token U errors by examining network responses before parsing.
AI Job Hunt Gets Smarter: A tutorial and repository for an AI-powered job search assistant using LlamaIndex and MongoDB, aimed at elevating the job search experience with Retrieval-Augmented Generation, is documented here.
LAION Discord
Falcon 2 Soars Above Llama 3 : The Falcon 2 11B model outshines Meta’s Llama 3 8B on the Hugging Face Leaderboard, exhibiting multilingual and vision-to-language capabilities, and rivaling Google's Gemma 7B.
: The Falcon 2 11B model outshines Meta’s Llama 3 8B on the Hugging Face Leaderboard, exhibiting multilingual and vision-to-language capabilities, and rivaling Google's Gemma 7B. GPT-4o Breaks the Response Barrier : OpenAI has released GPT-4o, notable for real-time communication and video processing; this model boasts improved API performance at reduced costs, matching human conversational speed.
: OpenAI has released GPT-4o, notable for real-time communication and video processing; this model boasts improved API performance at reduced costs, matching human conversational speed. RAG Meets Image Modelling : Discussion centered on RAG integration with image generation models highlighted RealCustom for text-driven image transformations and mentioned Stable Diffusion adapting CLIP image embeddings in place of text.
: Discussion centered on RAG integration with image generation models highlighted RealCustom for text-driven image transformations and mentioned Stable Diffusion adapting CLIP image embeddings in place of text. HunyuanDiT: Tencent's Chinese Art Specialist : Tencent introduces HunyuanDiT, a model claiming state-of-the-art status for Chinese text-to-image conversion, proving its mettle by demonstrating fidelity to prompts despite its smaller size.
: Tencent introduces HunyuanDiT, a model claiming state-of-the-art status for Chinese text-to-image conversion, proving its mettle by demonstrating fidelity to prompts despite its smaller size. AniTalker Animates Portraits with Audio: Launch of the AniTalker framework, facilitates the creation of lifelike talking faces from static images using provided audio, capturing nuanced facial expressions more than just lip-syncing.
OpenInterpreter Discord
GPT-4 Outpaces its Predecessor: Enthusiasts within the community have noted that GPT-4o is not only faster, delivering at 100 tokens/sec, but also more cost-efficient than the previous iterations. There's particular interest in its integration with Open Interpreter, citing smooth functionality with the command interpreter --model openai/gpt-4o .
Llama Left in the Dust: After experiencing the performance of GPT-4, one member shared their dissatisfaction with Llama 3 70b, alongside concerns over the high costs associated with OpenAI, which tallied up to $20 in just one day.
Apple's Reticence Might Fuel Open-Source AI: Speculation abounds on whether Apple will integrate AI into MacOS, with some members doubtful and preferring open-source AI solutions, implying a potential uptick in Linux utilization among the community.
Awaiting O1's Next Flight: Anticipation is high for the upcoming TestFlight release of an unnamed project, with members sharing their advice and clarifications on setting up test environments and compiling projects in Xcode.
The March Toward AGI: A spirited discussion relating to the progress toward Artificial General Intelligence (AGI) has taken place, with participants exchanging thoughts and resources, including a Perplexity AI explanation that sheds light on this frontier.
LangChain AI Discord
ChatGPT's Wavering Convictions: Engineers noted that ChatGPT now sometimes contradicts itself, diverging from its former consistency in responses. Concerns were raised about the tool's reliability in maintaining a steady line of reasoning.
LangChain Troubleshooting Continues: Engineers have moved to from langchain_community.chat_models import ChatOpenAI after LLCHAIN deprecation, but face new challenges with streaming and sequential chains. The slow invocation time for LangChain agents, especially with large inputs, has led to discussions on the potential for parallel processing to alleviate processing times.
AI/ML GitHub Repos Get Spotlight: Favorite AI/ML GitHub repositories were exchanged, with projects like llama.cpp and deepspeed receiving mentions amongst the community.
Socket.IO Joins the Fray: An engineer contributed a guide on using python-socketio to stream LLM responses in realtime, demonstrating client-server communication to handle streaming and acknowledgments.
Show and Tell with AI Flair: Shared projects included a Medium article on Plug-and-Plai integrations, a multimodal chat app utilizing Streamlit and GPT-4o, a production-scaling query for a RAG application with ChromaDB, and a Snowflake cost monitoring and optimizer tool in development.
Chat Empowers Blog Interaction: A post discussing how to enable active conversations on blog content using Retrieval Augmented Generation (RAG) was shared, further fueling interest in integrating advanced AI chat features on websites.
Blogging Platform Face-Off: Users debated the merits of Substack versus Bluesky for blogging needs, concluding that while Bluesky can support threads, it lacks comprehensive blogging features.
Reducing AI Compute Consumption: There's a focus on minimizing AI compute usage, with links shared to initiatives like Based and FlashAttention-2 that are paving the way to more efficient AI operations.
Dependency Dilemmas: Members are vexed by outdated dependencies, including peft 0.10.0 and others, and are adjusting them manually for compatibility, with a reluctant call for pull requests issued to rectify the situation.
CUDA Quandaries: A report surfaced about a member facing CUDA errors in an 8xH100 GPU environment, which was later mitigated by switching to a community axolotl cloud image.
QLoRA Model Mergers and Training Continuation: Queries and discussions arose about integrating QLoRA with base models without compromising precision. Additionally, conversations centered on the mechanics of resuming training from checkpoints using ReLoRACallback , as documented in the OpenAccess-AI-Collective axolotl repository.
Voice Assistant Not All Giggles: Technical community is puzzled by the choice of a voice assistant's giggling feature, considering it inappropriate and distracting for professional use. Workarounds like rephrasing commands could tame this quirk.
Mixed Review on GPT-4o's Book Recognition Task: GPT-4o's ability to enumerate books displayed on a shelf received mixed criticism, securing only a 50% accuracy, which leaves room for improvement despite its commendable speed and competitive pricing.
AGI Hype Debated: Skepticism prevails over imminent Advanced General Intelligence (AGI), as diminishing returns are observed in the leap from GPT-3 to GPT-4, while GPT-5's buzz overshadows current model refinements.
Long-Term GPT-4 Impact Still Foggy: Long-term predictions for impacts of GPT-4 and its iterations remain speculative, with the engineering community still exploring their full spectrum of capabilities.
Simon Tweets LLM Insights: Simon W's Twitter update could be a potent catalyst for conversation about the latest developments and challenges in large language models.
CUDA Troubles with Tinygrad: An inquiry about using CUDA=1 and PTX=1 on an Nvidia 4090 led to a recommendation to update Nvidia drivers to version 550 after PTX generation errors occurred.
GNN Potential in Tinygrad: The implementation of Graph Neural Networks (GNNs) within tinygrad was compared to PyG solutions, and a reference was made to a potentially quadratic time complexity CUDA kernel, with GitHub code provided for insight.
Aggregation Aggravation in Tinygrad: A user shared a Python function for feature aggregation test_aggregate.py and highlighted difficulties with advanced indexing and where calls during backpropagation; masking and the einsum function emerged as possible solutions.
Advance Indexing Issues: Advanced tinygrad features like setitem and where aren't supported with advanced indexing (using lists or tensors), leading to a discussion on alternative approaches, including the use of masking and einsum.
Tinygrad's Convolution Convolution: Ventures into optimizing the conv2d backward pass in tinygrad hit a snag with scheduler and view changes, sparking deliberations on whether a conv2d reimplementation would solve shape compatibility problems.
DiscoResearch Discord
German TTS Needs Input: A guild member issued a call to action for assistance in creating a list of German YouTube channels that offer high-quality podcasts, news, and blogs for training a German text-to-speech (TTS) system.
MediathekView as a Source for TTS Data: Utilizing MediathekView, participants discussed its usefulness in obtaining German-language media, with the ability to download subtitle files, recommended for curating content for TTS training.
Exploring MediathekView Data Download and API: Among the discourse, it was mentioned that the entire MediathekView database might be downloadable, and a JSON API available for content access; reference to a GitHub repository for related tools was noted.
New German Tokenizer Touted: A member drew attention to the "o200k_base" tokenizer's efficiency, which necessitates fewer tokens for German text than the prior "cl100k_base" tokenizer, also comparing it against known tokenizers like Mistral and Llama3, but no specific links were shared for this point.
Tokenizer Research and Training Resources Shared: Those with an interest in tokenizer research were directed to Tokenmonster, an ungreedy subword tokenizer and vocabulary training tool compatible with multiple programming languages.
Cohere Discord
Community Awaits Support: Users in the Cohere guild reported delays in receiving support responses, with one user reaching out in <#1168411509542637578> and <#1216947664504098877> to voice this issue. A response promised active support staff, requesting more details to assist.
Command R RAG Grabs Limelight: An engineer was "extremely impressed" by Command R's RAG (Retriever-Augmented Generation) capabilities, touting its cost-effectiveness, precision, and fidelity even with lengthy source materials.
Collaboration Call in Project Sharing: The #project-sharing channel saw a member, Vedang, express interest in teaming up with another engineer, Asher, on a similar project, underlining the community's collaborative spirit.
Members Spread Their Medium Influence: Amit circulated a Medium article that dives into using RAG via the Unstructured API, aimed at structuring content extractions from PDFs—potentially useful for engineers working with document processing.
Emoji Greetings Dismissed as Noise: Casual exchanges of greetings and emojis like "<:hammy:981331896577441812>" were deemed non-essential and omitted from the professional engineering discourse of the guild.
LLM Perf Enthusiasts AI Discord
GPT Rivalry Heats Up : Engineers are speculating on the use of Claude 3 Haiku and Llama 3b Instruct for automated scoring and entity extraction tasks; the debate extends to the efficiency of using a Pydantic model for such applications.
: Engineers are speculating on the use of and for automated scoring and entity extraction tasks; the debate extends to the efficiency of using for such applications. Constraining AI's Creativity for Precision : The discussion includes the potential benefits of constrained sampling when utilizing outlines in vllm or sglang to aid in precise entity matching, pointing towards more controlled outputs.
: The discussion includes the potential benefits of when utilizing to aid in precise entity matching, pointing towards more controlled outputs. GPT-4o Update Unveiled : OpenAI's spring update was the talk of the forum, featuring a new YouTube video showcasing updates to ChatGPT.
: OpenAI's spring update was the talk of the forum, featuring a new YouTube video showcasing updates to ChatGPT. Celebrity Meets AI: Engineers shared their reactions to OpenAI choosing Scarlett Johansson as the voice for GPT-4o, signaling a blurring line between celebrity and artificial intelligence.
Skunkworks AI Discord
Introducing Guild Tags : Effective May 15, Guild Tags will accompany usernames, manifesting membership in exclusive Guilds; Admins note, AutoMod will monitor these tags.
: Effective May 15, will accompany usernames, manifesting membership in exclusive Guilds; Admins note, will monitor these tags. Guilds Offer Exclusive Community Spaces: Guilds, representing exclusive community servers, currently enjoy limited availability and admins cannot manually add servers to this selective feature.
Alignment Lab AI Discord
Fasteval Bids Farewell: The Fasteval project has been discontinued, and the creator is seeking someone to take over the project on GitHub. Channels related to the project will be archived unless ownership is transferred.
AK Enigma Resurfaces: A message from angry.penguin mentioned that AK is back, implying the return of a colleague or project named AK. The context and significance were not provided.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
OpenAI ▷ #annnouncements (2 messages):
OpenAI unveils GPT-4o with free access: OpenAI announced new flagship model GPT-4o and introduced free access to features like browse, data analysis, and memory with certain limits. Plus users will get up to 5x higher limits and earliest access to new features including a macOS desktop app and advanced voice and video capabilities.
GPT-4o launches with real-time multimodal capabilities: The new GPT-4o model can reason across audio, vision, and text in real-time, broadening its application scope. Text and image input are available starting today, with voice and video capabilities rolling out in the coming weeks.
OpenAI ▷ #ai-discussions (1085 messages????????????):
Voice Mode Glitches Spark Hope for Update: Multiple users reported issues with the voice feature disappearing from the ChatGPT app, prompting speculation that this might signal an upcoming update. One user noted, "I restarted the app and it's gone lmao" while another speculated that they might be integrating a new generative voice model.
Google Keynote Leaves Mixed Impressions: Google's latest I/O event, which highlighted Gemini 1.5 and other advances, received a mixed response. While some users praised its integrations with Android and Google Suite, others found it lengthy and underwhelming compared to OpenAI's more concise presentations.
GPT-4o Availability Confusion: Users debated the accessibility and features of GPT-4o, indicating some confusion around its release. Despite differing views, there was general agreement that the model is available on iOS and offers enhanced token limits.
Claude's Superior Long-Form Reasoning: Members discussed Claude Opus's superior performance in handling complex, long-form tasks, particularly over GPT-4o. One pointed out, "If I feed 200 pages of original story to Opus... GPT and Gemini flatly can not."
Eager Anticipation for Future AI Updates: The community expressed eagerness for anticipated updates from both Google and OpenAI. Features like extended context windows, new voice capabilities, and text-to-video AI are especially awaited.
OpenAI ▷ #gpt-4-discussions (261 messages????????):
Per-GPT Memory Not Yet Available: A member inquired about cross-session context memory for custom GPTs, which another user clarified was not rolled out yet, linking to the OpenAI Help article. They confirmed that once available, memory will be per-GPT and customizable by creators.
GPT-4o Enhances Speed and API Use: Discussions highlighted that GPT-4o is significantly faster than GPT-4, with members noting improvements despite the same output token limits. Official announcements and benchmarks can be viewed in detail here.
Custom GPTs and Model Updates: There were questions regarding the integration of GPT-4o with custom GPTs, with a consensus that existing custom GPTs are not currently using GPT-4o. It was noted that more updates are expected, hopefully making it accessible within custom GPTs soon.
Plus and Free Tier Capabilities: Members discussed the usage caps for GPT-4o, with Plus users allowed 80 messages every 3 hours and free-tier users expected to have significantly lower limits, though exact details were noted to vary based on demand.
Voice and Multimodal Features Rolling Out: There's anticipation for GPT-4o's new audio and video capabilities, which will first be available to select partners through the API and then to Plus users in the coming weeks. Details and rollout plans can be found in OpenAI’s announcement.
OpenAI ▷ #prompt-engineering (51 messages????):
Moderation filter in Gemini 1.5 stumps user: A user reported that specific keywords like "romance package" cause their application to fail due to what seems like an unintended moderation filter. Despite changing defaults and generating new API keys, the issue persists, leading to discussions about safety settings and syntax errors.
GPT-4o struggles with creativity: Users reported that GPT-4o, while faster than GPT-4, struggles to understand prompts for creative tasks like writing assistance. It often echoes back rough drafts instead of providing intelligent revisions, indicating a potential issue with its comprehension abilities.
Prompt testing with GPT-4o: Another user suggested testing prompts with GPT-4 and GPT-4o, specifically songs like "The XX Intro" and "Tears in Rain" to compare sensory input descriptions. This practical approach aims to reveal differences in how each model processes and describes sensory information.
Challenges in generating specific image views with GPT-4o: A user encountered difficulties getting GPT-4o to generate detailed, cross-sectional side views of floors for a platformer game. The model often produces incorrect perspectives or simple squares, leading to a discussion about the limitations and potential need for iterative guidance with tools like Dall-E.
Iterative feedback with Dall-E and GPT-4o: It was noted that while GPT-4o can't 'see' images created by Dall-E, users can iteratively guide it by feeding its outputs back into the model. This process, although labor-intensive, can help achieve more accurate results, even though the model struggles with tasks requiring spatial awareness and image cropping.
OpenAI ▷ #api-discussions (51 messages????):
Odd Moderation Filter Issue with Gemini 1.5 : A user reported persistent failures when their application processes requests related to "romance packages," despite having no active blocks. Another member suggested explicitly disabling safety settings and verifying through different tools, but the issue remained unresolved.
: A user reported persistent failures when their application processes requests related to "romance packages," despite having no active blocks. Another member suggested explicitly disabling safety settings and verifying through different tools, but the issue remained unresolved. Discussions on GPT-4o's Performance : Users noted that GPT-4o is faster but less capable of understanding specific tasks compared to GPT-4. Members mentioned struggles with getting creative content and accurate revisions, with the model often echoing user's inputs.
: Users noted that GPT-4o is faster but less capable of understanding specific tasks compared to GPT-4. Members mentioned struggles with getting creative content and accurate revisions, with the model often echoing user's inputs. Sharing Prompts for Sensory Descriptions : A member encouraged others to compare GPT-4 and GPT-4o by using prompts like “Provide detailed sensory input description of the "The XX Intro" song” to observe differences in output. This was done to analyze the models' handling of sensory descriptions for instrumental songs.
: A member encouraged others to compare GPT-4 and GPT-4o by using prompts like “Provide detailed sensory input description of the "The XX Intro" song” to observe differences in output. This was done to analyze the models' handling of sensory descriptions for instrumental songs. Challenges with Generating Specific Art with AI : Another user highlighted difficulties in using GPT-4 and GPT-4o to generate cross-section images for a platformer game. Despite multiple attempts and adjusted prompts, the models often produced inaccurate or undesired views.
: Another user highlighted difficulties in using GPT-4 and GPT-4o to generate cross-section images for a platformer game. Despite multiple attempts and adjusted prompts, the models often produced inaccurate or undesired views. Iterative Process for Image Adjustment with AI: Another discussion focused on using DALL-E and model tools to create and adjust images iteratively. Users shared experiences of guiding the model incrementally to achieve more accurate image outputs, despite limitations in the model's ability to “see” and self-evaluate its work.
OpenAI ▷ #api-projects (2 messages):
ChatGPT Clone Inquiry: A user asked the community if anyone has created or could create a ChatGPT-like application using the 3.5 model. The unique requirement is that the messages sent and received by users can be monitored by the organization.
Perplexity AI ▷ #general (993 messages????????????):
32k vs 128K Token Controversy: People questioned if GPT-4 truly supports 32k tokens, with someone asserting that GPT-4's large context window is primarily for specific models like GPT-4o and Sonar Large. Further, GPT-4o, available now, offers a 128K context window, far exceeding 32k.
GTP-4o Rollout Reactions: Members enthusiastically commented on GPT-4o's impressive speed and performance compared to GPT-4 Turbo. One user shared an insightful YouTube video about GPT-4o's capabilities, expressing excitement over the new functionalities.
Concerns Over Opus' New Policies: Discussion arose about Anthropic's strict new terms of service for Opus, effective June 6th, which many found restrictive. An Anthropic policy link was shared, detailing controversial clauses like banning LGBTQ content creation.
Claude 3 Opus Still Holds Value: Though some users praised GPT-4o for its speed and accuracy, Claude 3 Opus was still considered excellent, especially for text summarization and emulating human-like responses. However, Opus' cost and usage limits remained significant concerns.
GPT-4o Use in Perplexity: Perplexity added GPT-4o to its lineup, with users testing and praising its high-speed responses and detailed contextual understanding. Many noted that GPT-4o offers 600 queries per day in Perplexity Pro, aligning with its API offering.
Perplexity AI ▷ #sharing (9 messages????):
Link to detailed jctrl. Discussion: A member shared a link to a Perplexity AI search result.
US Puts Search Link Provided: Another member shared a link to a Perplexity AI search result.
Question on GPT-4 Internet Connectivity: A member questioned if GPT-4 is linked to the internet and included a link to their Perplexity AI search.
Magnesium Search Result Shared: A member posted a link to information about magnesium via Perplexity AI search.
Request for Help in Spanish: A message contained a link to a Perplexity search in Spanish regarding a task someone needed help with: necesito-hacer-unos.
Discussion on Aroras: A member referenced a Perplexity search about Aroras with a link to the results: How-are-aroras.
Ski Resort Information Shared: A link was shared to Perplexity AI results on ski resorts: Ski-resort-with.
Market Size Query: Another member linked to a Perplexity AI search regarding market size information: Market-size-of.
Perplexity AI ▷ #pplx-api (4 messages):
Difference between Llama models : A member queried about the difference between llama-3-sonar-large-32k-chat model and llama-3-8b-instruct . Another member clarified that the chat model is "fine-tuned for conversations".
: A member queried about the difference between model and . Another member clarified that the chat model is "fine-tuned for conversations". Optimal timeout settings for long inputs: A member faced timeout issues with an input of approximately 3000 words using a timeout setting of 10000ms and sought advice on optimal settings. There was no follow-up functionality or additional information provided in response to the query.
Unsloth AI (Daniel Han) ▷ #general (622 messages????????????):
Instruction vs. Base Model for Finetuning: A user asked whether to use the instruction version or base version of Llama-3 for finetuning. Another user advised to start with the instruction model for smaller datasets and switch to the base model if performance is inadequate ("try instruct first, if it's bad u can try base and see which u like better").
ThunderKittens Kernel Released: A member highlighted the release of ThunderKittens, a new kernel claimed to be faster than Flash Attention 2, GitHub - ThunderKittens. It was noted for its potential impact on inference speeds, with the possibility of it being used for training as well.
Synthetic Data Required for Typst Fine-tuning: Users discussed the creation of synthetic data for fine-tuning models to process "Typst," with suggestions to create 50,000 examples to train effectively ("if no data for that exists - you have to synthetically create it"). The challenge of generating this large dataset was acknowledged.
Imminent Multimodal Model Support: It's teased that support for multimodal models is coming soon in Unsloth. Users can look forward to new releases in the following week, including multi-GPU support ("multi GPU next week most likely tho").
Celebration of 1 Million Downloads: The community celebrated Unsloth achieving over 1 million model downloads on Hugging Face, attributing the success to the active user base and continuous use and support from the community (Tweet).
Unsloth AI (Daniel Han) ▷ #random (37 messages????):
OpenAI release anticipation: Members are speculating about the upcoming release from OpenAI. One member hopes for an open-source model but doubts linger, with one stating, "I doubt they will ever do that" due to potential bad press or competition.
AI plateau and "AI winter" discussions: There are mentions of the press discussing an "AI winter" and a plateau in commercial AI models. One member pointed out, "even if development slows down they are still quite comfortable at the top".
Llama as the potential SOTA and its implications: If Llama becomes state-of-the-art, one member speculates that Meta might stop releasing it and expects OpenAI to respond aggressively. "If Llama becomes SOTA I’ll bet Meta doesn’t release it."
vllm project using Roblox for meetups: There is a proposal to have virtual meetups in Roblox, similar to the vllm project's practice. One user supports the idea, saying, "you can like do progress reports or roadmaps, while we jump around with our avatars."
Discord summarizing with AI and concerns: Members are aware that Discord is summarizing chat content using AI, with some concerns about compliance with European data laws. "That sounds like a headache with European data laws..."
Link mentioned: Ah Shit Here We Go Again Gta GIF - Ah Shit Here We Go Again Gta Gta Sa - Discover & Share GIFs: Click to view the GIF
Unsloth AI (Daniel Han) ▷ #help (283 messages????????):
Bitsandbytes causes import issues in Colab: Members discussed encountering an AttributeError caused by bitsandbytes on Colab despite following the installation guide from the Unsloth GitHub repo. Solutions included checking for GPU activation, ensuring the correct runtime setup, and installing dependencies accurately.
Multi-GPU Support Pricing Concerns: Discussion revolved around the high cost of multi-GPU support at $90 per GPU per month. Members debated the feasibility of usage-based pricing or partnering with cloud services like AWS to make it financially viable for non-enterprise users.
Technical Hurdles with Model Saving and Loading: Users faced issues with merging finetuned models using save_pretrained_merged() and loading using the FastLanguageModel.from_pretrained() method. Errors included missing adapter configuration files and conflicts during model loading, with resolutions suggesting reinstallation or version updates.
Finetuning Questions and Insights: Members addressed various finetuning-related queries such as loading finetuned models, using specific datasets, and resolving issues tied to specific environments like Kaggle and Conda. Discussions highlighted the importance of proper version compatibility and environment setup.
Feedback on Open Source and Commercial Models: Broad feedback was shared about balancing the line between open source contributions and sustainable commercial models. Us