Participants
In total, 10,535 participants completed the online experiment. Of these, 340 participants (3.23%) were excluded because they failed the attention check (but see Table 2 for equivalent results when data all participants are included), leaving an analytical sample of N = 10,195 participants from 24 countries (see Table 3 for descriptive statistics per country). Participants were recruited from university student samples, from personal networks and from representative samples accessed by panel agencies and online platforms (MTurk, Kieskompas, Sojump, TurkPrime, Lancers, Qualtrics panels, Crowdpanel and Prolific). Participants were compensated for participation by a financial remuneration, the possibility of a reward through a raffle, course credits or no compensation. There were no a priori exclusion criteria; everyone over 18 years old could participate. Participants were forced to answer all multiple choice questions, hence there was no missing data (except for 36 people who did not provide a valid age). The countries were convenience sampled (that is, through personal networks), but were selected to cover six continents and include different ethnic majorities and religious majorities (Christian, Muslim, Hindu, Jewish, Eastern religions, as well as highly secular societies). Table 3 displays the method of recruitment and compensation per country.
Table 3 Descriptive statistics per country Full size table
The study was approved by the local ethics committee at the Psychology Department of the University of Amsterdam (Project #2018-SP-9713). Additional approval was obtained from local IRBs at the Adolfo Ibáñez University (Chile), the Babes-Bolyai University (Romania), the James Cook University (Singapore), Royal Holloway, University of London (UK) and the University of Connecticut (USA).
Sampling plan
We preregistered a target sample size of n = 400 per country and 20–25 target countries. The preregistered sample size and composition allowed us to look at overall effects, effects within countries and between countries. Because we applied a Bayesian statistical framework, we needed a minimum of 20 countries to have sufficient data for accurate estimation in cross-country comparisons109. However, our main interest were overall effects, rather than effects for individual countries. With approximately 8,800 participants, we would have sufficient data to reliably estimate overall effects, especially as the source effect is within-subjects. Data collection was terminated by 30 November 2019. The data from ten participants who completed the survey after this termination date were retained in the dataset.
Materials
The study was part of a larger project on cross-cultural effects related to religiosity (see Supplementary Information for details about the project). The full translated survey for each included country can be found at osf.io/kywjs/. The relevant variables for the current study were individual religiosity, the manipulated source of authority and the ratings of the statements.
Participant religiosity was measured using established items taken from the World Values Survey80, covering religious behaviours (institutionalized such as church attendance and private such as prayer/mediation), beliefs, identification, values and denomination (see Supplementary Table 5 for the exact items). Besides having high face-validity, these measures have been applied cross-culturally in other studies79,110,111. A Bayesian reliability analysis using the Bayesrel package112 indicated good internal consistency of the religiosity measure, McDonald omega = 0.930 (0.927, 0.931). The religious membership item was removed from the scale, as this item was only moderately correlated with the other items (item-rest correlation = 0.608, all others >0.706) and dropping it improved the reliability to omega = 0.939 (0.938, 0.941). The remaining seven individual religiosity items were transformed on a 0–1 scale (to make each item contribute equally to the scale), tallied to create a religiosity score per participant, and grand mean standardized for the analyses.
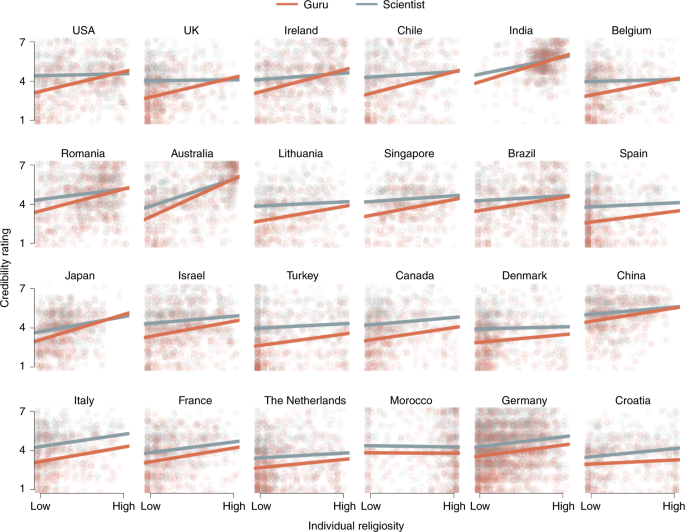
The experimental stimuli consisted of two gobbledegook statements that were attributed to a spiritual guru and to a scientific authority (within-subjects). We created two versions of the statement, manipulating (1) the background of the frame: an opaque new age purple galaxy background versus an opaque dark green chalkboard with physics equations; (2) the accompanying grey-scale photo of the alleged source: a man in robes (photo of José Argüelles) versus a man in an old-fashioned suit (photo of Enrico Fermi); and (3) the reported profession: spiritual leader versus scientist. In addition, in the introductory text, the source was further announced as ‘Saul J. Adrian—a spiritual authority in world religions’ versus ‘Edward K. Leal—a scientific authority in the field of particle physics’, names counterbalanced. The names were fictitious and the photos were taken from Wikipedia with re-use permission. The two versions of the text were three-sentence, 37/38-word statements. We generated the statements using the New Age Bullshit Generator (http://sebpearce.com/bullshit/), that combines new age buzzwords in a syntactically correct structure resulting in meaningless, but pseudo-profound sounding texts67. The two versions of the text were counterbalanced between sources. Participants were randomly assigned to the scientific–spiritual or the spiritual–scientific ordered condition. The stimuli in each language are provided at osf.io/qsyvw/.
The main outcome variable pertained to judgements of the importance and credibility of gobbledegook, measured on a seven-point Likert scale from not at all important/not at all credible to extremely important/extremely credible, respectively. A multiple choice recognition item for the source that expressed the statement was included as a manipulation check. In our preregistration, we did not specify that we would exclude participants based on incorrect recall of the source of the statement. We therefore kept all observations in the dataset for the main analyses and additionally ran the models without the observations for which the source was not recalled correctly. The results of this robustness check are provided in Table 2. For exploratory purposes, we also measured reading and processing time for the statement, as well as depth of processing. The latter was operationalized as the number of items correctly identified as having appeared in the statement. Participants were presented with a list of ten words, including five targets and five distractors, and were asked to select the words that they recognized from the statement.
Procedure
Participants received a link to the Qualtrics survey, either by email, social media or through an online platform. After reading the instructions and providing informed consent, they first completed items for a separate study about religiosity and trustworthiness. Next, they were presented with the first statement and source stimulus, rated its importance and credibility, completed the manipulation check to validate that they registered the source, and completed the word recall item. These elements were then repeated for the second statement. After that, participants completed items about body–mind dualism. Finally, they provided demographics, a quality of life scale, the religiosity items and were given the opportunity to provide comments. It took about 10 minutes to complete the entire survey (median completion time was 11.4 minutes).
Data analysis
We used the R package BayesFactor76 to estimate and test the multilevel Bayesian regression models113,114. The multilevel Bayesian modelling approach allows us to systematically evaluate the evidence in the data under different models: (1) across all countries the effect is truly null; (2) all countries share a common non-zero effect; (3) countries differ, but all effects are in the same (predicted) direction; and (4) in some countries the effect is positive, whereas in others the effect is negative. The models differ in the extent to which they constrain their predictions, from the most constrained (1) to completely unconstrained (4). We refer to these models as the null model, the common effect model, the positive effects model and the unconstrained model, respectively. Note that although the predictions from model (3) are less constrained than those from model (2), it is more difficult to obtain evidence for small effects under the latter model because it assumes that the effect is present in every country, rather than only in the aggregate sample. When applied to our hypothesis for the source effect, evidence for (1) would indicate that people from these 24 countries do not differentially evaluate credibility of claims from a guru or a scientist, evidence for (2) would indicate that on average people from these 24 countries consider claims from a scientist more credible than from a guru (or vice versa) with little between-country variability in the size of the effect, evidence for (3) would indicate that in all of the 24 countries, people consider claims from a scientist more credible than from a guru (or vice versa), but there is cultural variation in the size of this effect, and evidence for (4) would indicate that in some countries people consider claims from a scientist more credible than from a guru, and in other countries people consider claims from a guru more credible than from a scientist, indicating cultural variation in the direction (and size) of the effect. We used the interpretation categories for Bayes factors proposed by Lee and Wagenmakers115, based on the original labels specified by Jeffreys116.
For the main effect of source (\({{{{\mathcal{H}}}}}_{1}\)), we specified the following unconstrained model. Let Y ijk be the credibility rating for the ith participant, i = 1,…, N, in the jth country, j = 1,…, 24, for the kth condition, k = 1, 2. Then Y ijk ~ N(μ + α j + v i β + r i δ j + x k γ j , σ2). Here, the term μ + α j serves as the baseline credibility intercepts with μ being the grand mean and α j the jth country’s deviation from the grand mean. The β term reflects the fixed effect of the level of education covariate. δ j is the jth country’s main effect of religiosity on credibility ratings. The crucial parameter here is γ j which is the source effect for the jth country. In the common effects model, we will replace γ i with γ. The variable x k = −0.5, 0.5 if k = 1, 2, respectively, where k = 1 indicates the scientist condition and the k = 2 indicates the guru condition. The variable v i is the standardized participant-level education covariate. The variable r i is the standardized religiosity score for each participant. Finally, σ2 is the variance in credibility ratings across participants.
To test the source-by-religiosity interaction for hypothesis 2, the model from (1) is extended by including an interaction term: Y ijk ~ N(μ + α j + v i β + r i δ j + x k γ j + r i x k θ j , σ2), where θ j is the parameter of interest, the religiosity × source interaction effect, with r i x k as the product of the experimental condition and the standardized individual religiosity score. The parameter estimates as reported in the results section are based on the full model from (2).
To systematically investigate which third variables should and should not be included in the statistical model, we used directed acyclic graphs117 to visually represent the causal relations between the variables in our data118,119,120. In short, this method entails specifying directed relations (arrows) between different constructs and measures (nodes) in a given design that allow one to intuitively reflect causal structures and determine which third variables should be accounted for and which should be ignored in the statistical model. Based on directed acyclic graphs created in the R package ggdag121, both country and level of education were identified as potential confounding factors that warranted inclusion, because they may affect both religiosity122,123 and overall credibility assessments (for example, due to scepticism). Country was therefore added as a clustering factor, while level of education was added as a fixed covariate in all models. We also ran the models while including all participant-level variables related to the primary measures, that is, gender124, age125, socio-economic status126,127, statement version (A or B) and presentation order (guru–scientist or scientist–guru). Note that including these covariates improved the model fit, but the qualitative results remain the same regardless of the (set of) covariates. See Supplementary Figs. 4–6 for details on the causal graphs and Table 2 for the primary results without any and with all covariates.
Prior settings
The BayesFactor package applies the default priors for ANOVA and regression designs128,129, in which the researcher can determine the scale settings for each individual predictor in the model. We used the settings for the critical priors in the multilevel models as proposed by Rouder et al.114, concerning the scale settings on μ γ , μ θ and \({\sigma }_{\gamma }^{2},{\sigma }_{\theta }^{2}\). The scale on μ γ , μ θ reflects the expected size of the overall source effect and source-by-religiosity effect, respectively, and is set to 0.4 (small–medium effect). The scale of \({\sigma }_{\gamma }^{2},{\sigma }_{\theta }^{2}\) reflects the expected amount of variability in these effects across countries. This scale is set to 60% of the overall effect, resulting in a value of 0.24. The prior scale for the overall between-countries variance was set to 1. We used 31,000 iterations for the Markov chain Monte Carlo sampling and discarded the first 1,000 iterations (‘burn-in’).
Deviations from preregistration
We deviated from the preregistration in the following ways. First, in our preregistration, we formulated a hypothesis about the interaction between source and perceived cultural norms of religiosity in one’s country. However, in retrospect, we realized this hypothesis lacked theoretical justification and the proposed analysis was methodologically suboptimal (see Supplementary Information for details on this analysis).
Second, as a stopping rule, we preregistered that data collection would be terminated (1) when the target of n = 400 per country was reached, or (2) by 30 September 2019. However, due to unforeseen delays in construction of the materials and recruitment, this deadline was extended to 30 November 2019. We did not download or inspect the data until after 30 November.
Third, we preregistered to only include countries where usable data from at least 300 participants was collected (that is, complete data from attentive participants). However, we decided to keep the n = 291 participants from Lithuania in the final sample, because the hierarchical models account for uncertainty in estimates from countries with smaller samples and removing these data will actually reduce the overall precision of the estimates. Moreover, it would simply be unfortunate to remove all data from a highly understudied country.
Fourth, we preregistered that we would use the R package brms130 to analyse the data and estimate model parameters. However, we ended up using the BayesFactor package76. This method is arguably more suitable for model comparison and calculating Bayes factors in particular. However, we also ran the models as preregistered and report these results in the Supplementary Information.
Fifth, we added level of education as a participant-level covariate to the models, which improved the model fits. Note that adjustments 3–5 did not qualitatively change any of the results (Table 2 and the Supplementary Information).
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.