Satellite data
To generate a full time series tailored to mountain areas, modeled data were downscaled using the full time series of MODIS snow cover maps and MODIS snow cover duration from the hydrological years 2000–2001 to 2019–2020.
Snow Cover Area (SCA) and Snow Cover Duration (SCD) were obtained by the products NASA-Moderate Resolution Imaging Spectroradiometer (MODIS) Daily L3 Global 500 m Grid, Version 6 (MOD10A1.006), available at https://nsidc.org/data/mod10a1. Data were processed for the whole period from February 24th, 2000, up to September 30th, 2020, considering the hydrological year as follows: for the Northern Hemisphere from 1st October to 30th September, for the Southern Hemisphere from 1st April to 31st March55. MOD10A1.006 products provide values of the Normalized Differential Snow Index (NDSI) that were transformed into snow cover fraction by using the linear approach proposed by Salomonson and Appel56. Snow cover fraction values were transformed into Snow Cover Area (SCA) values by averaging over the different mountain ranges. Data were processed considering yearly and seasonally average for: September–October–November (SON), December–January–February (DJF), March–April–May (MAM) and June–July–August (JJA). The Snow Cover Duration (SCD) values were derived by using the procedure described in Notarnicola 202057. All the processing was carried out using the Google Earth Engine (GEE) platform58. MODIS SCA products were extensively validated in different mountain areas in the last two decades, indicating an average accuracy of around 94.2%59,60,61. In mountain areas, the accuracies strongly depend on the illumination conditions and cloudiness. For SCD validation, the comparison with ground data determined the following performances: Mean Absolute Error = 21.1 days, bias = − 3.1 days, R = 0.84. The reader can refer to Notarnicola 202057 for full details on the snow parameter validation.
Modeled data
The modeled data considered in the work are derived from the simulation of the Famine Early Warning Systems Network (FEWS NET) Land Data Assimilation System (hereafter named FLDAS)62. These data contain different land surface parameters obtained from the Noah 3.6.1 model63, which simulates the important biogeophysical, hydrological and energy balance processes, thus providing a physical approach to snow modeling. They are produced at monthly basis with a global coverage, and their main characteristic with respect to other models (e.g. GLDAS) is the higher spatial resolution of 0.1° × 0.1° (10 km × 10 km).
The simulation was forced by a combination of the Modern-Era Retrospective analysis for Research and Applications version 2 (MERRA-2) data and Climate Hazards Group InfraRed Precipitation with Station (CHIRPS) 6-hourly rainfall data that have been downscaled using the NASA Land Data Toolkit.
Snow modeling for FEWS NET was developed and originally implemented by the NOAA National Operational Hydrologic Remote Sensing Center (NOHRSC), using a spatially distributed land surface model (LSM) operating within the Land Information System (LIS) software framework version 6. LIS provides a means for high-performance land surface modeling utilizing multiple potential forcings63. Additional specifications are available at https://ldas.gsfc.nasa.gov/FLDAS/FLDASspecs.php.
From FLDAS, two main parameters were addressed: snow cover fraction, which can be directly compared with the MODIS SCA products, and snow depth, used to derive SCD maps by considering different thresholds (2 cm, 5 cm, 10 cm).
It is worthwhile mentioning the limitations of the data used in this study. The data used in the downscaling approach can be affected by several uncertainties. MODIS satellite data can offer data with the highest possible ground resolution (500 m) to observe mountain areas with a good level of accuracy. However their estimates can have some limitations, being affected by cloud cover and with limited penetration into the canopy16,57. Moreover, these data cover only the period from 2000 onward, thus limiting the attribution of long-term trends. For this purpose, the combination with modeled data offers the possibility to extend the perspective of monitoring to longer time scale. There is a large small-scale variability remaining, due to microclimatic effects not captured in the gridded dataset, and considerable uncertainties can be related to this aspect. For this reason, no altitude analysis was carried out. On the other hand, the results are appropriate to quantify long-term regional trend patterns and impacts on water resources in the specific areas analyzed.
Study area
The analysis is carried out at global scale in different mountain ranges as delineated in the layer Global Mountain Biodiversity Assessment (GMBA)64. The layer reports 1003 mountain ranges by using the place name references that easily allow intercomparison among areas.
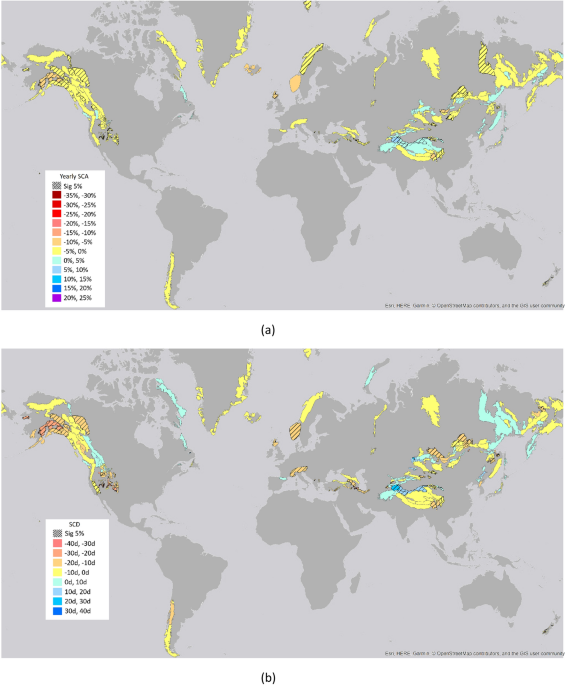
A further selection was done on the areas based on the use of satellite and modeled data. Specifically, only those with persistent and seasonal snow cover were considered in the following analysis. They were selected by considering yearly mean snow cover area (SCA) averaged over the period 2000–2001 to 2017–2018 (18 years) larger than 10%, and snow cover duration (SCD) averaged over the same period longer than 20 days. Moreover, same areas were not considered as modeled data provided always null values. After this thresholding, 380 areas remain for yearly SCA and SCD values. For SON period, 291 areas were selected, for DJF 459, for MAM 402 and for JJA 117.
Comparison of FLDAS snow cover data with MODIS SCA (MOD10A1, 500 m) and SCD (derived parameter) over the period 2000–2018
As the first step in the downscaling procedure, the capacity of the FLDAS snow cover parameter to reproduce the snow seasonal cycle in mountain areas at global level was assessed. FLDAS snow cover mean values were compared with MODIS SCA and SCD as extracted from the product MOD10A1 from the hydrological years 2000–2001 to 2017–2018. This timeframe was selected as these data are the basis for the training and test of the downscaling approach. The remaining years (2018–2019, 2019–2020) are used as blind test to further assess the robustness of the downscaling approach. The products were compared considering the mean at area level at yearly basis, for different elevation belts and season based (SON, DJF, MAM, JJA) and per latitude belts. The following figures of merit were considered: Bias, Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), Pearson correlation coefficient R. Only areas with averaged SCD > 20 days and averaged SCA > 10% were included in the analysis.
Here, the analysis on the elevation was performed considering the mean elevation within each area. The reason of such analysis is related to the ground resolution of the FLDAS snow cover. The results are presented in Table 1.
Table 1 Comparison between MODIS SCA and SCD and modeled FLDAS data (*Pearson correlation significant at 5% level). For SCD, different thresholds of Snow Depth (SD) were tested. For each data set, in parenthesis the number of points used in the evaluation is indicated. Full size table
The comparison between MODIS and FLDAS for the period 2000–2001 to 2017–2018 indicates that FLDAS can reproduce well the snow behavior throughout the year and as well for both SCA and SCD. For most of the cases, the differences between MODIS and FLDAS are within the limit of the known uncertainties on the MODIS SCA maps61,65. Major problems can be found for high percentage of forest cover (> 50%), for higher elevations (> 4000 m) and areas with small size (< 500 km2). These uncertainties can be both related to MODIS limitations, such as the detection of snow under forest, and to spatial resolution of FLDAS, which may limit the detection of snow in smaller areas. Regarding the SCD parameter, the threshold of SD = 5 cm was selected for further analysis as a good compromise considering the performances.
Approach for downscaling based on Artificial Neural Networks (ANNs)
The main aim of the proposed procedure is to downscale the FLDAS data by using MODIS data sets as a reference through an approach based on Artificial Neural Networks (ANNs). This procedure is aimed at improving the modeling of FLDAS specifically over mountain areas by using Earth Observation data with a higher ground resolution and a sufficient length of the time series.
Downscaling approaches constitute empirical methods to derive relationships between large-scale variables (predictors) and observed local variables (predictands). As predictands, several variables can be used related to high resolution imagery and/or geomorphology features, as well as both station and gridded data sets21,22,66.
Among the different approaches, ANNs were selected because of their versatility, capability to deal with different types of data and previous experiences19,23,67,68.
ANN structure includes many parallel computing units (named neurons) arranged in different layers and linked through adjustable connections (named weights). The weights are the adaptive parts of the set of nonlinear basis functions which compose the ANNs, and are set initially in a random way. Afterward they are adapted to the specific problem by the training process carried out on input/output cases available in the training data set. The training set is a subset of the entire data set which is normally divided into training, validation and test data sets. The training process is an iterative process with the aim to minimize a cost function, for example the average squared error between the network outputs and the targets69. ANNs have been used for several purposes: among them the estimation of biophysical parameters67,70,71, pattern recognition and downscaling approaches20. In this work, a classical feed-forward network with error backpropagation algorithm was adopted.
As a first step, ANNs were used by testing different input configurations and model structure (in terms of number of layers and neurons). For the training, test and validation, all the hydrological years from 2000–2001 to 2017–2018 were used. The total data sets used had the following number: 6840 for yearly SCA and SCD, 5238 for SON, 8262 for DJF, 7236 for MAM and 2106 for JJA. An AAN model was derived separately for the yearly SCA, SCD and the four periods, SON, DJF, MAM and JJA. The subdivision among training, test and validation was 60%, 20%, 20%. As a blind test, data from hydrological years 2018–2019 and 2019–2020 were used, to further assess the capability and robustness of the networks to correct the bias between FLDAS data and MODIS in unforeseen data samples.
The potential input features were selected based on their likely physical relationship to snow cover extent and snow cover duration. The considered input features were of two types: fixed variables which can describe the specificity of the location, such as the mean elevation, the latitude, the average of the reference period of snow cover extent and snow cover duration21,72,73. As indicated in Table 1, the comparison between MODIS and FLDAS data shows sensitivity with respect to these parameters. Along with these fixed variables, the dynamic component was also considered by taking into account the changes from location to location and from one year to the other.
Temperature was considered a key input feature, as it regulates whether a location will receive rain or snow and also determines the intensity of snowfall. The other key feature directly related to snow variability was the snowfall values. Both parameters were derived from MERRA2 reanalysis data.
The results indicate that the best performances are obtained when using both fixed parameters and meteorological variables, together with a network of 2 layers with 25 neurons. When considering both fixed parameters and meteorological variables, the relationship between MODIS and FLDAS notably improves. After this analysis, the considered input variables were the following:
Averaged SCA and SCD (avSCA, avSCD) for the hydrological years from 2000–2001 to 2017–2018
Temperature (T) and precipitation (P)
Mean elevation over the area (meanH)
Centre latitude of the area (L)
Tree cover in % (TC).
Regarding the configuration, several tests were run, considering from one to four internal layers and from 10 to 50 neurons for each layer. The results indicate that beyond 2 layers the performances worsen, whereas increasing the number of neurons the performances remain quite stable. These results are shown in the supplementary material (Fig. S3). The flowchart of the procedure is shown in Fig. 6.
Figure 6 Flowchart of the overall procedure. It is shown the case where the target variable is the yearly SCA. The same applies for the other considered target variables that is SCD, SON SCA, DJF SCA, MAM SCA, JJA SCA. Full size image
The ANN approach was applied to the baseline period from 2000–2001 and 2017–2018, where both FLDAS model simulations and MODIS estimates were available. In this period, the years 2018–2019 and 2019–2020 were used as blind test. After that, the trained ANN models were applied to the period 1982–1999.
It is worthwhile mentioning that the target variable was considered the difference between MODIS estimates and FLDAS model. For example in the case of SCA, it was diffSCA = SCA(model) − SCA(MODIS). In this way, the ANN model after the training was able to predict the difference between the two sources of information. To obtain the original target, it is sufficient to add the estimated difference to the corresponding value from FLDAS model. This selection of the target variable is relevant especially when the trained networks were applied to the period 1982–1999, where no MODIS estimates are available.
To quantify the model uncertainty introduced by the ANN empirical regression models, the confidence intervals of the regression error were estimated by using the bootstrap method, based on a resampling technique74,75,76,77. This approach is quite efficient, simple to implement and provides accurate uncertainty estimates. Moreover, it requires no prior knowledge about the distribution function of the underlying population (e.g. normality), being a distribution-free inference method74,75.
The bootstrap approach was based on a resampling with replacement of the original data set. From each bootstrap data set, a bootstrapped regression model is built, and the model outputs are computed. Different bootstrap data sets give rise to a distribution, and a probability density function (PDF) of the model output can be built. Thus, the model uncertainty of the estimates provided by the ANNs can be quantified in terms of confidence intervals78. However, the computational cost could be high when the training data set and the number of parameters in the regression model are large79. Several tests were run in order to evaluate the adequate number of bootstrap runs as a compromise between stability of the results and computation burden. Considering 50, 100 and 500 runs, it was found that between 100 and 500 runs the results on the confidence interval remain stable, and for this reason the number of bootstrapped data sets was set to 100. To train 100 networks, the processing time was around 3 h in a normal PC. After the processing, the mean estimates with the associated 95% confidence intervals were calculated.
As the last point, it is worthwhile underlining that the downscaling approach was applied on an area-based average, considering that downscaling at pixel basis would have required a more demanding process, including specific modeling of fine scale processes. In fact, the coarse resolution of the initial modeled data and the scales at which they are conceived need to be considered in the downscaling approaches80.
Uncertainty evaluation: confidence interval from bootstrap, blind validation, hypothesis test
The source of uncertainties can be related to the uncertainties in the reference data sets, in the model parametrization, as well as in the proposed downscaling approach. To have confidence on the FLDAS downscaled outputs with MODIS datasets, one important part is that the downscaled outputs can represent the current state of the snow changes reasonably well. This means that the downscaling output ability to represent the MODIS data in the baseline period (2000–2001 to 2017–2018) is important to have reasonable confidence on the reliability of the SCA and SCD change, computed over the whole period 1982–2020. The aim of the uncertainty analysis is, therefore, to evaluate the performance of the downscaling method in reproducing the mean value and variability of observed variables for the baseline period68,81.
Three complementary methods were employed to analyze the uncertainty of the output of the statistical downscaling model. First the downscaled results were evaluated on the data of 2018–2019 and 2019–2020 as a further validation to check the robustness of the approach in a new data set. In this first part of the validation, the reference data are always the MODIS derived parameters.
Second, it was important to quantify the impact of the downscaling accuracy on the consideration of the snow cover and parameter change analysis. The main questions are: how reliable are the estimated trends on the downscaled analysis? How do they compare with the MODIS trends in the period where both are available? To answer these questions, the following procedure was set. Once the trends were detected and the related changes derived by using the Mann–Kendall approach and the Sen’s slope respectively, two hypothesis tests were run: non- parametric Mann–Whitney test to check the mean consistency of the downscaled and original MODIS trends, and Kolmogorov–Smirnov test for trend preservation on Mann–Kendall results68,82. The data which had significant trends but not satisfying the hypothesis tests were excluded from the final analysis.
Third, if the values of the changes detected by the Sen’s slope were smaller than the confidence intervals obtained with the bootstrap procedure, i.e. the associated uncertainties derived from the ANN procedure, these data were excluded from the final analysis.
These three steps are detailed in the next section.
Downscaling results from application of ANN approach
Validation with MODIS data
Here the performances on the ANN results are presented in two ways. The results on the overall data sets obtained by using the bootstrap procedure imply a resampling of the input data and then a cross-validation is carried out in the procedure. To further assess the robustness of the procedure, the models were applied to the years 2018–2019 and 2019–2020, considering this as a full blind test as these data were never used in the derivation of the ANN models.
The results in Table 3, when compared with those in Table 1, clearly indicate the improvement achieved in the downscaling procedure. The downscaling approach specifically contributed to improve the values of the Bias, MAE and RMSE. When comparing these values in Tables 1 and 2, overall it was found a reduction of root mean squared error of 76%, of mean absolute error of 79%, of bias of 96% and improvement of the correlation coefficient of 12%. The results on the blind test sets (2018–2019, 2019–2020) are consistent with the ANN test data, thus indicating a good capability to reproduce the original MODIS data also when the ANN models are applied to completely unforeseen data. For sake of comparison in Table 3, the performances on the downscaled data are subdivided in different categories as in Table 1. For each category, a clear improvement is found. More in details, the bias values are always below 1%, apart for the JJA months where it is at 8%. The MAE values range between 1.3% and 4.5% and the RMSE values between 2.5% and 6%. All these values are within the limits of the accuracy found for MODIS SCA and SCD values57,61,65.
Table 2 Performances of the ANNs for yearly SCA, SCD, SON SCA, DJF SCA, MAM SCA, JJA SCA. For each data set, in parenthesis the number of points used in the evaluation is indicated. Values in bold are significant at 5% level. Full size table
Table 3 Comparison between MODIS SCA and SCD and modeled FLDAS data after the downscaling procedure (*Pearson correlation significant at 5% level). For each data set, in parenthesis the number of points used in the evaluation is indicated. Full size table
Statistical analysis
Mann–Kendall and Sen’s slope
The presence of a monotonic increasing or decreasing trend in time was detected by using the non-parametric Mann–Kendall (M–K) statistics, for its capability to deal with the presence of outliers in comparison to Pearson correlation83. Then, the slope (change per unit time) of the linear regression was estimated by using a simple non-parametric procedure developed by Sen (1968)84 together with a 100 (1- α) % two-sided confidence interval. Finally, considering the number of years, the slope was transformed into the total change value for each of the analyzed variables85.
Hypothesis tests
One important part was the evaluation of the consistency of the downscaled data with respect to the MODIS data and the capability to reproduce the mean values and the trend81.
First, the Wilcoxon-Mann-Withney (W-M-W) test was used to assess whether the two samples of data (downscaled and MODIS data set) are likely to derive from the same population. It is a non-parametric test and thus can be applied without any assumption on the data distribution. This test was applied to the downscaled and MODIS data for the period 2000–2020.
Moreover, because of the unavoidable discrepancies between the downscaled data and the original MODIS values, the resulting trends may be different82,86,87. In order to see if the trends of the downscaled data preserve the ones of the MODIS data, the Kolmogorov-Smirnoff approach was used. This approach is used to assess whether two samples come from the same distribution. In this case it was applied to the trend estimated by the M–K approach on the downscaled data, and compared with those derived from the MODIS images. As reported in Table 4, for all the parameters the trends were preserved with significance at 5% level.
Table 4 Statistical analysis for the different parameters: N° area-total number of areas analyzed; Sig. M–K trend: the areas with significant trends at 5% level for Mann–Kendall (M–K); Sig. W-M-W test: the areas found with no significant difference for the Wilcoxon-Mann-Withney (W-M-W) statistics; Sig. Changes > CI-Bootstrap: areas whose changes are larger than the uncertainties associated with the downscaling procedure and defined with the Confidence Interval of the bootstrap approach; K-S trend preservation: check for the trend preservation with Kolmogorov–Smirnov (K-S) at 5% significance level. Full size table
Selection of changes based on the confidence interval
As the last step, the changes detected by the trend analysis (M–K and Sen’s slope) were compared with the uncertainties associated with downscaling procedure through the confidence interval obtained by the bootstrap approach. The changes smaller than the confidence interval were discarded and not considered in the further analysis.
The results of the application of the previous tests are summarized in Table 4. All the analyses presented in this work are based on the data which satisfy all these tests.