Power calculation and study registration
A power calculation was conducted for an interaction effect (repeated measures ANOVA), in G*Power 3.1.9.7 with f = 0.10, α = 0.05, power = 0.90, 4 groups, correlation between repeated measures r = 0.60, resulting in a minimum required total sample size of N = 288 (n = 72 per group). According to the general rule of thumb for Cohen’s f statistic, f ≥ 0.10 < 0.25 is a small effect, f ≥ 0.25 < 0.40 is a medium effect, and, f ≥ 0.40 a large effect (see Cohen, 1988)25. We opted for a small effect size as a similar study as ours, conducted by van Hedger et al.16, also using a repeated-measures ANOVA data analysis approach, reported interaction effects type ([2] natural vs. urban soundscapes) by time ([2] pre-to-post exposure) on mood, whereby Cohen’s d for negative affect was between 0.36 and 0.40. These results were non-significant, as the study was underpowered for detecting small effects. The interaction effects observed concerning cognition in that paper, applying the same tests as in the present paper, were large (d between 0.71 to 0.76). Since we were interested in detecting effects on mood and to study yet unknown effects on state paranoia, we opted for and intermediate effect size between small and medium.
The study was pre-registered at aspredicted.org (study name: “Sounds_Online”, trial identifier: #67702, https://aspredicted.org/d5j7j.pdf) on 06/04/2021.
Recruitment and in- and exclusion criteria
The study was programmed using Inquisit 526 (https://www.millisecond.com) and accordingly run on the Millisecond server. Participants were recruited from the crowdsourcing platform Prolific and received 10€ reimbursement for their full participation. Adult individuals were pre-screened on Prolific (i.e., visibility of the study only for candidates with a suited profile) concerning fluent German language skills (as this was the study language), having no diagnosed lifetime mental illness, and having no hearing difficulties. Pre-screened individuals could then access the study, where in- and exclusion criteria were checked further. This included no regular substance or drug intake, no suicidal thoughts, or tendencies, and availability of headphones for the purpose of the study.
Study procedure
After providing informed consent, sociodemographic information was assessed, including education, income, and further variables, which were assessed for potential additional or exploratory analyses, but for the sake of conciseness are not reported in this paper. Psychosis liability was assessed. For an according overview on sample characteristics, see Table 2. Hereafter, pre-test assessments were conducted, including an assessment of mood (depression, anxiety), paranoia, the digit-span, and n-back tasks. Participants were randomized to one of four sound conditions: (1) low diversity traffic noise soundscape n = 83, (2) high diversity traffic noise soundscape n = 69, (3) low diversity birdsong soundscape n = 63, or (4) high diversity birdsong soundscape n = 80, (for details on the stimuli, see “Stimuli” section). The soundscapes each lasted for exactly 6 min. Participants were instructed to set their audio system volume to 80% (which was piloted with members of our research unit beforehand and deemed to be an optimal average volume) and to listen to the sounds until the end, when participants were required to continue by clicking with their mouse. Participants were told that a code, consisting of two spoken digits (in German), would be audible towards the end of the sound presentation, which they were required to type in correctly afterwards. This was implemented to assure listening-compliance and attention. After the sound presentation, the pre-test measures were repeated. Finally, several items to assess perceived sound quality, including beauty, pleasantness, and monotony (vs. diversity) were presented.
Table 2 Descriptive sample data and between-group differences for socio-demographic variables. Full size table
Sample
Initially, N = 401 individuals started the survey. Of those, n = 76 quit during the sociodemographic assessment, n = 24 lacked pre-test data, and n = 6 lacked post-test data. These n = 106 cases were excluded from the analyses, resulting in a final sample of N = 295. Of these, some participants had incomplete post-test data (n = 10 missing digit span, 5 missing n-back, and n = 8 missing the qualitative assessments [sound rating]).
For detailed information and inferential statistics comparing the groups at baseline see Table 2. The participants were in their middle to late twenties on average and there were in tendency more males than females. Net income was mostly reported to be in the lowest category (i.e., < 1.250€, 40–50% of participants of all groups), but also between 5 and 20% of participants did not wish to reveal their monthly net income. Positive symptom frequency levels did not differ significantly between the groups, albeit there were relatively marked descriptive differences (p = 0.058). The values were mostly similar and within a confidence interval range that has previously been reported for healthy individuals19. Due to the trend-level nature of the differences in positive symptom frequency, we decided to repeat the main analyses, controlling for this variable as covariate in the repeated measures ANOVAs.
Measures
For all mood and the paranoia scales, item scores were computed (i.e., summing up responses on all items and dividing this by the number of items). This way, the interpretation of scores is facilitated, as it corresponds to the Likert-scale of the respective measure.
Psychosis liability
Psychosis-liability or sub-clinical psychosis levels was assessed using the Community Assessment of Psychic Experiences (CAPE)19, in its German version, to assesses lifetime positive, negative and depressive symptoms (http://www.cape42.homestead.com/index.html). The CAPE, including the German version, has been validated extensively17. Items refer to the lifetime prevalence of specific symptoms, rated on an ordinal response scale for frequency (categories: 1 = ‘never’, 2 = ‘sometimes’, 3 = ‘often’, 4 = ‘nearly always’). The total scale consists of 42 items, whereby the positive symptom scale includes 20 (e.g., ‘Do you ever feel as if things in magazines or on TV were written especially for you?’), the negative symptom scale 14 (e.g., ‘Do you ever feel that your mind is empty?’), and the depressive symptom scale 8 items (e.g., ‘Do you ever feel like a failure?’). To test for comparative baseline levels across all groups in psychosis liability, mean frequency scores for the positive symptom subscale was used, for which Mossaheb and colleagues have provided descriptive data for individuals with ultra-high risk for psychosis (n = 84) vs without risk (i.e., healthy controls; n = 81)19. The positive dimension (frequency) of the CAPE had excellent internal consistency in the present sample, with Cronbach’s α = 90.
Mood and paranoid symptoms
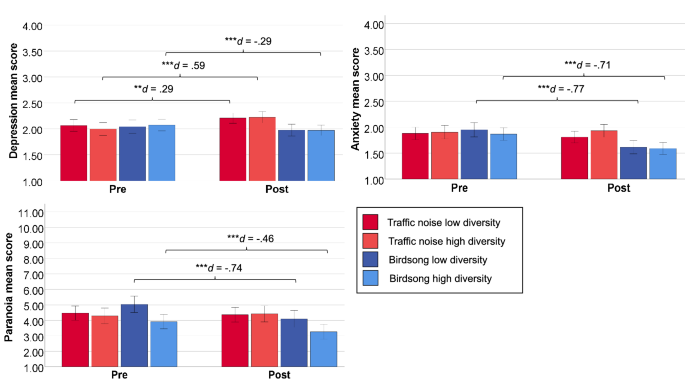
Mood was assessed with the State Trait Anxiety Depression Inventory (STADI)27. The scale contains 40 items, whereby the same 20 items are once presented in trait and once in state format. Only the latter was used in the present study. The scale differentiates between depression (low euthymia [inverted items], dysthymia) and anxiety (hyperarousal and worry), whereby each of the subscales is assessed by 5 items. The response format is a 4-point Likert (1 = ‘not at all’, 4 = ‘strongly applies’). Internal consistency (Cronbach’s α) at pre-test was good both for the state anxiety (0.85) and depression (0.86) scales.
Paranoia was assessed with a brief, change sensitive state version of the paranoia checklist, which has been validated and comparable to the long, state adapted 18-item version17. The scale comprises 3 statements (e.g., ‘I need to be on my guard against others’, ‘Strangers and friends look at me critically’, ‘People try to upset me’), rated on an 11-point Likert-scale (each from 1 to 11) for the degree of agreement to the statement, associated distress and conviction, at present. The latter two categories were only presented if the rating of agreement to the statement was > 1 (which accordingly often results in a large amount of missing data). In the present study, only agreement was evaluated. Internal consistency at pre-test was acceptable with Cronbach’s α = 0.78.
Cognition
To assess digit span cognitive performance, both the forward and backward version were used, as available in Inquisit 526 [retrieved from https://www.millisecond.com] which is based on the original task reported by Woods et al.28. Two parameters are recommended for evaluation: the two-error maximum length (TE_ML) and the maximum length recalled (ML). The two-error maximum length is defined as the last digit span a participant gets correct before making two consecutive errors while the maximum length is the digit span that a participant recalled correctly during all trials irrespective of the number of errors in-between. Starting with a successive visual presentation of 3 digits, the participants need to correctly recall a by 1 digit increasing sequence of digits and reproduce it by clicking on the correct digits in correct order. After two wrongly recalled sequences of the same length, the digit span is decreased by 1 digit until the digit span length again reaches the starting point of 3. The total amount of trials is 14 making the shortest span possible 3 digits long and the longest span 16 digits long. The participants were explicitly reminded not to use any memory assisting methods such as paper and pencil. The dual n-back task, also available in the Inquisit 526 (retrieved from https://www.millisecond.com) was assessed. The task is based on the original work by Jaeggi et al.29. It consists of 4 experimental blocks demanding 2-back and 3-back level performance. While performing the task, subjects pay attention to their computer screen while also listening to a computer audio. On each trial a blue square appears in one out of eight grid-like locations around a central fixation cross, while at the same time a (German) letter is presented via the headphones. In the 2-back block condition, the subjects are instructed to press the “A” button on their keyboard when the current square position matches the square position from two trials before. Subjects are also instructed to press the “L” button on their keyboard if the spoken letter matched the letter two trials before. The same instruction, but having to match stimuli 3 trials back, is provided for the 3-back condition. In the present study, participants trained each condition once, and then went on with the experimental blocks. The performance parameter was the so-called d prime value calculated as the proportion of ((visual_TotalHits − visual_TotalFA) + (auditory_TotalHits − auditory_TotalFA)/2)/number of total experimental blocks. The highest possible d prime (greatest sensitivity) was 6.93 and the lowest was 0. Visual hits are defined as correct responses with respect to the location of the square and auditory hits are defined as the correct responses with respect to the spoken letter. Visual false alarms (FA) are defined as responses in the absence of a target in the visual domain, thus with respect to the location of the square and auditory false alarms are responses in the absence of a target in the auditory domain, thus with respect to the spoken letter.
Soundscape perception
The participant’s perception of the soundscapes was assessed using a one item questionnaire per dimension (diversity/monotony, pleasantness, and beauty). Participants were asked to report on a 0 to 100 visual scale how diverse/monotone, beautiful, and pleasant they had perceived the soundscape they had listened to during the experiment. The items have been formulated by the authors themselves while the use of an aesthetic rating of the soundscapes per se was a replication from the van Hedger et al.16 study where we exchanged the “like–dislike” affective response with a more detailed aesthetic rating splitting the response up into a pleasantness and a beauty dimension. The dimension of diversity/monotony has been to perform a manipulation check on diversity for the soundscapes used in the present study.
Stimuli
The soundscapes for all four categories have been generated in the same way. Single sound snippets were gathered and then adapted and merged within the audio software Steinberg Cubase10. An exemplary visualization of the resulting soundscape can be seen in the Supplementary Material (see Supplementary Fig. 1). For the nature category a database of birdsong recordings (https://www.xeno-canto.org/explore/region) from a central European origin was used. For the low diversity birdsong condition, eight recordings from the same two species were used (common chiffchaff & wood warbler). For the high diversity birdsong condition, the same approach was chosen, but recordings from eight different bird species were used to create the soundscape (garden warbler, honey buzzard, woodlark, Eurasian sparrow hawk, coal tit, greenshank, common crane, and black woodpecker). In both birdsong conditions, additionally subtle water and wind sounds were played in the background, to create a constant auditory experience. For the traffic noise conditions, sound snippets from eight car recoding’s (https://freesound.org/search/?q=city) were used for the low diversity traffic noise condition while audio-snippets from eight diverse sources of noise pollution associated with the city were used for the high diversity traffic noise condition (ambulance siren, construction, trucks, train, motorcycle, airplane, bus and fire-fighter siren). In both traffic noise soundscapes, a constant subtle traffic flow was audible in the background.
To ensure that all soundscapes were perceived with a similar loudness level, all soundscapes were engineered to have a similar loudness value. The loudness values from all four conditions range between 19.4 and 27.8 loudness units relative to full scale (LUFS). All soundscapes had a duration of 6 min. Prior to the experiment the soundscapes have been presented to a small set of pilot participants rating the similarity of the audio level ensuring a comfortable audio level across all conditions. As a result, at the beginning of the experiment, participants were instructed to set their headphone loudness level to 80%. Soundscapes can be accessed openly via this link https://osf.io/4y3vh/.
Statistical analyses
Analyses were run in SPSS 27 (IBM Corp., 2020). To test the differences of all measures at baseline, several univariate analyses of variance (ANOVA) were run. In order to test the effects of high vs. low diverse traffic noise vs. birdsong soundscapes on mood, paranoia, and cognition, repeated measures analyses of variance (ANOVA) were run testing for a 2 (timepoint: pre vs. post) × 2 (soundscape type: birdsong vs. traffic noise) × 2 (diversity: low vs. high) interaction effect. The analyses were once run with all participants, and then only with those who entered at least one of the digits (control of compliance of listening to audio, see “Study procedure” section) correctly, to check for the robustness of findings. In order to further check for the robustness of effects on mood and cognition repeated measures ANOVAs were run controlling for baseline sample differences on sample characteristics or outcomes (i.e., state paranoia, age and positive symptoms) as covariates. To check the robustness of effects on paranoia a univariate analysis of covariance (ANCOVA) with paranoia at baseline as covariate and post-test paranoia as outcome, predicted by type and diversity as factors, was computed. Significant interactions (i.e., of interest were the type × time and type × diversity × time) interactions identified for any of the outcomes were followed up by subsequent detailed post-hoc-tests. To explore mean differences between the qualitative ratings of soundscapes (i.e., beauty, pleasantness, and monotony vs. diversity), a one-way multivariate analysis of variance (MANOVA) was conducted. In case of significant omnibus tests indicating global differences across the qualitative sound rating dimensions, follow-up between group t-tests were conducted. Due to the exploratory nature of the study, no p-level correction was applied.
The partial eta squared effect size was used to interpret the ANOVA based analyses, with the corresponding rule of thumb defining η2 = 0.01 as a small effect size, η2 = 0.06 as a medium effect size and η2 = 0.14 as a large effect size30. Cohen’s d effect size was used to interpret post-hoc test effect sizes, with the corresponding rule of thumb defining a value of ≥ 0.2 as a small effect size, a value of ≥ 0.5 as a medium effect size and a value of ≥ 0.8 as a large effect size. The criteria for interpreting the effect size for Hedge’s g stem from the corresponding rule of thumb with the same definition30.
Ethics statement
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all participating subjects. The experimental protocol was approved by the ethical committee from the University Clinic Hamburg Eppendorf.